بقلم: يوسف | محرر أدوات الذكاء الاصطناعي · صوت تحريري بإشراف بشري
كم عدد أحرف P في كلمة Google؟ يجيب ذكاء Google الاصطناعي: اثنان. ويؤكد أن هناك “بالضبط حرف r واحد في كلمة ‘poop'”، بينما يهجئ كلمة “journalism” كـ “j-o-u-r-n-a-d-i-s-m” مدعياً احتواءها على حرفي d. أما اسم الرئيس الأمريكي فيهجئه “t-r-p-u-m” رغم تأكيده احتواء اللقب على حرف P واحد فقط.
هذه ليست مجرد أخطاء محرجة، بل نافذة على قيود جذرية في طريقة عمل نماذج اللغة الكبيرة التي تقود ثورة الذكاء الاصطناعي التوليدي. Google تعيد تصميم محرك البحث الأشهر في العالم ليعتمد على هذه التقنية، لكن النتائج تذكرنا أن الذكاء الاصطناعي أبعد ما يكون عن المثالية.
“العد داخل الكلمات كان تحدياً معروفاً لنماذج اللغة الكبيرة، ونحن نعمل على إصلاح هذه المشكلة تحديداً”، أقرت Google لموقع TechCrunch. لكن المشكلة ليست خطأً برمجياً بسيطاً، بل عيب هندسي أساسي في البنية المعمارية للمحولات (transformers) التي تدير معظم نماذج الذكاء الاصطناعي اليوم.
صارت مشاكل التهجئة مزحة دائرة في مجتمع الذكاء الاصطناعي لسنوات. كلما كشفت شركة عن نموذج جديد، يسارع المختبرون لسؤاله: كم حرف r في كلمة “strawberry”؟ هذه النماذج، القادرة على برمجة تطبيق في ثوانٍ أو حل مسائل حيرت الرياضيين لعقود، بمستوى طفل روضة في التهجئة.
Matthew Guzdial، باحث الذكاء الاصطناعي في جامعة Alberta، يوضح السبب: “نماذج اللغة الكبيرة تعتمد على هندسة المحولات، والتي لا تقرأ النص فعلياً. ما يحدث عند إدخال استفسار هو ترجمته إلى ترميز رقمي. عندما يرى النموذج كلمة ‘the’ يحصل على ترميز واحد لمعنى ‘the’، لكنه لا يعرف شيئاً عن الحروف T وH وE”.
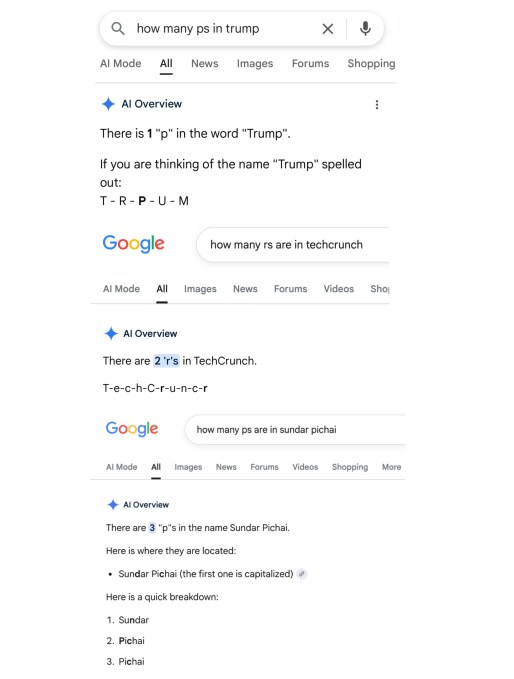
هذه ليست المرة الأولى التي تتعثر فيها ميزة AI Overviews من Google. عند إطلاقها أول مرة، استشهدت بمنشورات ساخرة من The Onion وReddit، ونصحت المستخدمين بأكل الصخور ووضع الغراء على البيتزا. كما أصلحت Google مؤخراً خطأً جعل البحث عن كلمة “disregard” يُظهر رداً يقول: “مفهوم، أخبرني عندما يكون لديك استفسار أو سؤال جديد!”
التحدي الحقيقي يكمن في طبيعة المحولات نفسها. هذه الأنظمة تقسم النص إلى وحدات تسمى “رموز” (tokens) قد تكون كلمات كاملة أو مقاطع أو حروف، حسب تصميم النموذج. بدلاً من “قراءة” النص كما يفعل البشر، تحول المحولات كل رمز إلى تمثيل رقمي، ثم تستخدم السياق لتوليد استجابة منطقية.
Sheridan Feucht، طالب دكتوراه يدرس قابلية تفسير نماذج اللغة الكبيرة في جامعة Northeastern، متشائم حول إمكانية الحل: “صعب تجاوز سؤال ماذا يجب أن تكون ‘الكلمة’ بالضبط لنموذج اللغة، وحتى لو اتفق خبراء اللغة على مفردات رموز مثالية، ستجد النماذج على الأرجح طرقاً لـ’تجميع’ الأشياء بطرق أخرى. تخميني أنه لا يوجد شيء اسمه مرمز مثالي بسبب هذا النوع من الضبابية”.
لكن هل هذا مهم حقاً؟ الباحثون لا يعتبرون التهجئة أولوية عاجلة لأن فائدة نماذج اللغة الكبيرة لا تكمن في قدرتها على عد الحروف. هذه النماذج تتفوق في فهم السياق وتوليد نصوص متماسكة وحل مسائل معقدة، ليس في مهام رياضية بسيطة مثل العد.
ومع ذلك، هذه الإخفاقات الصارخة مفيدة كتذكير بضرورة عدم الثقة العمياء في مخرجات الذكاء الاصطناعي. عندما يخطئ ذكاء Google في تهجئة اسم الشركة نفسها، يطرح ذلك أسئلة أعمق حول حدود الثقة المعقولة في عصر يزداد فيه اعتمادنا على هذه الأنظمة في اتخاذ قرارات مهمة.
المفارقة أن Google تراهن مليارات الدولارات على جعل الذكاء الاصطناعي التوليدي محور منتجها الرئيسي البالغ عمره 29 عاماً، بينما النظام لا يستطيع أداء مهام بديهية مثل عد الحروف. هذا لا ينفي قيمة التكنولوجيا، لكنه يؤكد أهمية فهم قيودها الحقيقية قبل منحها ثقة مطلقة في مهام حساسة.