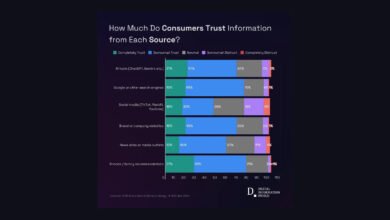
خوارزمية جوجل الجديدة تضغط نماذج الذكاء الاصطناعي دون فقدان الجودة
تخيل أن تشغل ChatGPT أو أي نموذج لغوي كبير على هاتفك الذكي بسرعة تفوق ما تحصل عليه الآن من السحابة بثماني مرات. هذا ما تعد به تقنية TurboQuant الجديدة من جوجل، وهي خوارزمية ضغط ثورية تقلل استهلاك الذاكرة بمقدار 6 مرات مع تسريع الأداء 8 مرات — دون أي تراجع في جودة الإجابات.
ما الذي تغيّر؟
تعمل TurboQuant على ضغط ما يُسمى بـ “key-value cache” في النماذج اللغوية، وهو المكان الذي يحتفظ فيه النموذج بالمعلومات من المحادثة السابقة لتجنب إعادة حسابها. في النماذج الحالية، تنتفخ هذه الذاكرة المؤقتة بسرعة مع كل سؤال وجواب، مما يجعل تشغيل النماذج على الأجهزة المحلية أمراً مستحيلاً عملياً.
الحل الذي طورته جوجل يضغط هذه البيانات بذكاء، مما يعني أن نموذجاً لغوياً كبيراً يمكن أن يعمل على جهازك بدلاً من الحاجة لإرسال استفساراتك إلى خوادم جوجل السحابية.
لماذا يهمك؟
هذا التطور يعيد تعريف معادلة الخصوصية والسرعة في الذكاء الاصطناعي. بدلاً من انتظار اتصال الإنترنت وإرسال بياناتك للسحابة، ستحصل على إجابات فورية محلياً. وبالنسبة للمطورين العرب، هذا يعني إمكانية بناء تطبيقات ذكاء اصطناعي تعمل في المناطق ذات الاتصال الضعيف — وهي ميزة تنافسية هائلة في أسواق مثل مصر والمغرب.
ولكن الأهم من ذلك، أن هذه التقنية قد تكون بداية النهاية لهيمنة الشركات الكبرى على معالجة البيانات. عندما تصبح النماذج المتقدمة قابلة للتشغيل محلياً، تنتفي الحاجة لدفع اشتراكات شهرية أو مشاركة بياناتك مع أطراف خارجية.
ما الذي لا يُقال؟
جوجل لم تكشف عن موعد إتاحة TurboQuant للمطورين، ولم تحدد ما إذا كانت ستكون مفتوحة المصدر أم مقتصرة على منتجاتها. كما أن الاختبارات الأولية لا تشمل نماذج متعددة اللغات، مما يثير تساؤلات حول أدائها مع النصوص العربية المعقدة.
هذا ليس مجرد تحسين تقني — إنه خطوة نحو ديمقراطية الذكاء الاصطناعي. السؤال الآن: هل ستسمح جوجل للجميع بالاستفادة من هذا التقدم، أم ستبقيه حكراً على خدماتها؟