
بقلم: نور | محررة الأبحاث والدراسات · صوت تحريري بإشراف بشري
عندما أراد فريق من معهد الابتكار التطبيقي في الإمارات إنشاء لوحة تقييم شاملة للنماذج اللغوية العربية، اكتشفوا مشكلة أكبر: المعايير نفسها تحتوي على عيوب منهجية. النتيجة كانت QIMMA قِمّة – أول لوحة تقييم عربية تفحص جودة المعايير قبل تشغيل النماذج عليها، وليس بعدها.
النهج التقليدي يجمع المعايير الموجودة ويشغل النماذج عليها مباشرة. QIMMA قررت فعل العكس تماماً: فحص كل عينة من الـ52,000 عينة عبر 109 مجموعة فرعية من 14 معياراً مصدرياً قبل أي تقييم. والنتائج؟ حتى المعايير المحترمة والواسعة الاستخدام تحتوي على مشاكل جودة منهجية تفسد النتائج بصمت.
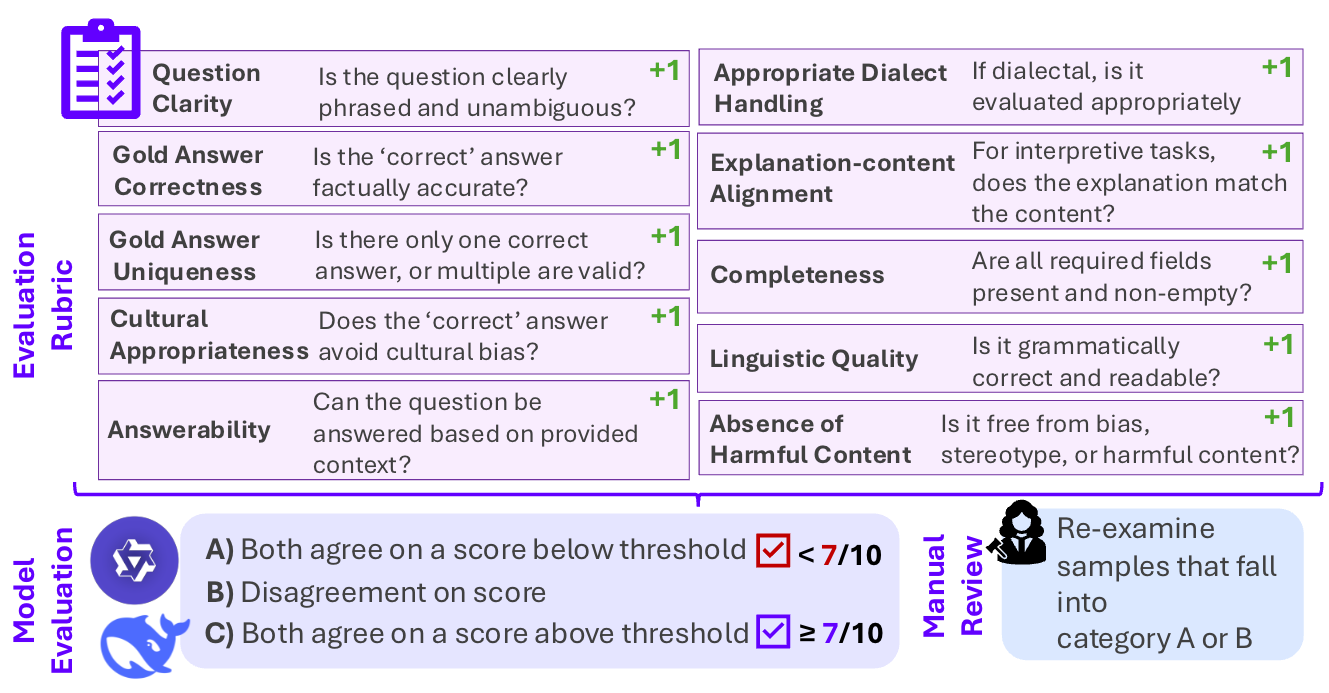
المنهجية تبدأ بتقييم آلي مزدوج: نموذجا Qwen3-235B-A22B-Instruct وDeepSeek-V3-671B يفحصان كل عينة مقابل معايير من 10 نقاط. اختيار نموذجين مختلفي تركيبة البيانات التدريبية يضمن حكماً أقوى من أي منهما منفرداً. العينات التي تحصل على أقل من 7/10 من أي نموذج تنتقل للمرحلة الثانية: مراجعة بشرية من متحدثين أصليين يتعاملون مع السياق الثقافي والتنويع اللهجي والتفسير الذاتي.
البيانات الخام صادمة. ArabicMMLU – أحد أهم المعايير العربية – خسر 436 عينة من أصل 14,163 (معدل إقصاء 3.1%). MizanQA سجل 2.3%، PalmX وصل لـ0.8%. حتى المعايير الأحدث لم تسلم: (وفقاً لتحليل الفريق) معدلات الإقصاء تتراوح من 0.0% إلى 3.1% عبر جميع المعايير المختبرة.
- مشاكل جودة الإجابات: فهارس ذهبية خاطئة أو غير متطابقة، إجابات خاطئة واقعياً، إجابات ناقصة أو نصوص خام غير مُعالجة
- عيوب النص والتنسيق: نصوص تالفة وغير مقروءة، أخطاء إملائية ونحوية منهجية، عينات مكررة تؤثر على الإحصائيات
- مشاكل الحساسية الثقافية: تعزيز قوالب نمطية وتعميمات أحادية تجاه مجتمعات عربية متنوعة
- عدم الامتثال للبروتوكول: عدم توافق الإجابات الذهبية مع بروتوكولات التقييم المحددة في الأوراق الأصلية
- مشاكل الترجمة والتكييف: أسئلة تبدو طبيعية بالإنجليزية لكنها محرجة أو منفصلة ثقافياً بالعربية
معايير البرمجة تطلبت تدخلاً مختلفاً. بدلاً من إقصاء العينات، نقح الفريق البيانات العربية في تكييفات 3LM لـHumanEval+ وMBPP+ مع الحفاظ على معرفات المهام والحلول المرجعية وحزم الاختبار دون تغيير. النسب مذهلة: 88% من مطالبات HumanEval+ و81% من MBPP+ احتاجت تعديلات تشمل التنقيح اللغوي وتحسينات الوضوح وتطبيع الاتساق المصطلحي وتصحيحات هيكلية.
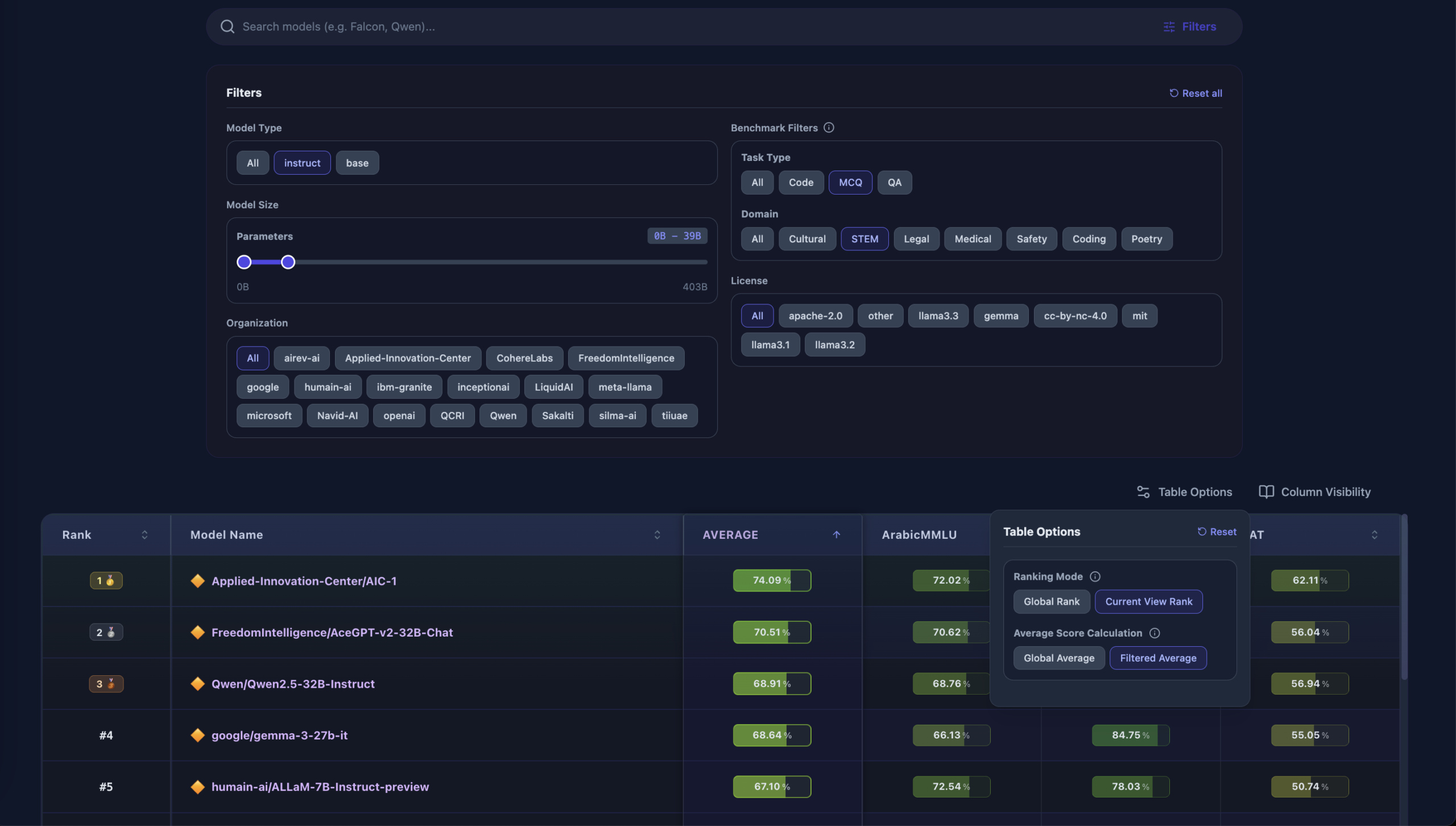
النتائج النهائية تكشف ديناميات معقدة. Qwen3.5-397B-A17B-FP8 يتصدر بمعدل 68.06%، لكن القصة أعمق من مجرد ترتيب. الحجم لا يضمن الأداء المتفوق – اللوحة تضم نماذج من 32B إلى 397B معامل، وعدة نماذج متوسطة الحجم تتفوق على أكبر منها في مجالات محددة. Jais-2-70B يحقق أعلى النقاط في ArabicMMLU (81.29) وArabCulture (83.24)، بينما يقود Karnak في 3LM STEM (93.10) وArabLegalQA (71.58).
التخصص العربي يحقق نتائج ملموسة في المهام الثقافية واللغوية، لكن البرمجة تبقى التحدي الأكبر. أعلى نقاط HumanEval+ (67.68) وMBPP+ (76.72) حققها Qwen3.5-397B متعدد اللغات، بينما النماذج العربية المتخصصة تسجل نقاطاً أقل بشكل ملحوظ. هذه الفجوة تطرح أسئلة مهمة حول توازن التخصص اللغوي مقابل القدرة التقنية العامة.
QIMMA تختلف جذرياً عن اللوحات الأخرى في عدة جوانب حاسمة. هي الوحيدة التي تجمع خمس خصائص معاً: مفتوحة المصدر، محتوى عربي أصلي بنسبة 99%، فحص جودة منهجي، تقييم البرمجة، وإتاحة مخرجات الاستدلال على مستوى العينة الواحدة. المحتوى العربي الأصلي يتجنب مشاكل الترجمة التي تصيب معايير أخرى، والاستثناء الوحيد هو تقييم البرمجة الذي يكون محايد اللغة بطبيعته.
اللوحة تستخدم إطار LightEval وEvalPlus وFannOrFlop للتقييم، مع قوالب مطالبات موحدة عبر ستة أنواع: الاختيار المتعدد العام، الاختيار مع مقطع سياق، الاختيار مع تعليمات محددة، الأسئلة المفتوحة، الأسئلة مع سياق، وملء الفراغ. كل المطالبات باللغة العربية، مع الحفاظ على مطالبات النظام الخاصة بالمعايير الأصلية عند الحاجة.
التغطية شاملة عبر سبعة مجالات: الثقافة (AraDiCE-Culture وArabCulture وPalmX)، العلوم (ArabicMMLU وGAT و3LM STEM)، القانون (ArabLegalQA وMizanQA)، الطب (MedArabiQ وMedAraBench)، الأمان (AraTrust)، الشعر والأدب (FannOrFlop)، والبرمجة (3LM HumanEval+ و3LM MBPP+). هذا التنويع يسمح بتقييم حقيقي للقدرة الشاملة وليس مجرد أداء في مجال واحد.
النظام يستخدم مقاييس مختلفة حسب نوع المهمة: دقة Log-Likelihood المطبعة للاختيار المتعدد، كتلة الاحتمال على الخيارات الذهبية للاختيار المتعدد متعدد الخيارات، F1 BERTScore مع AraBERT v02 للأسئلة التوليدية، وPass@1 لتقييم البرمجة. هذا التنويع في المقاييس يضمن قياساً عادلاً عبر أنواع المهام المختلفة.
الكود متاح بالكامل على GitHub مع ورقة بحثية تفصيلية توثق كامل المنهجية والنتائج. هذه الشفافية تتيح للباحثين تكرار النتائج والبناء عليها، وهو ما يفتقر إليه كثير من اللوحات الأخرى التي تنشر النقاط الإجمالية فقط دون تفاصيل التنفيذ.
QIMMA لا تدعي إضافة معايير جديدة – بل تطبق فحص جودة صارم على المعايير الموجودة. هذا النهج قد يبدو محافظاً، لكنه يكشف حقيقة مقلقة: حتى أفضل معاييرنا تحتاج تنظيف قبل الاعتماد عليها لاتخاذ قرارات مهمة حول قدرات النماذج. السؤال الآن: كم من نتائج التقييم “المعتمدة” بُنيت على بيانات معيبة؟







