بقلم: نور | محررة الأبحاث والدراسات · صوت تحريري بإشراف بشري
حققت شركة Dharma AI نتيجة تهز أسس صناعة الذكاء الاصطناعي: نموذج بـ 3 مليارات معامل فقط سجل أداءً متفوقاً على كل النماذج التجارية العملاقة في مجال استخراج النصوص، (وفقاً لبحث Dharma AI) متجاوزاً Claude Opus 4.6 وGPT-5.4 وجميع منافسيه بفارق واضح وتكلفة منخفضة 52 مرة.
لثلاث سنوات، هيمن افتراض واحد على قرارات شراء الذكاء الاصطناعي للمؤسسات: النموذج الأكبر هو الأقوى. هذا المنطق بدا مقنعاً لأنه كان صحيحاً – GPT-4 تفوق على كل نموذج أصغر عند إطلاقه، وتكررت القصة مع Claude 3 وGemini 1.5 وكل جيل جديد من النماذج الرائدة في 2025. قوانين التحجيم لـ OpenAI أثبتت العلاقة التجريبية بين حجم النموذج والقدرة.
لكن فريق Dharma AI اكتشف متغيراً مختلفاً بالكامل. في بحثهم المنشور، قاسوا الأداء والتكلفة واستقرار الإنتاج جنباً إلى جنب لأول مرة، والنتائج تضع علامة استفهام كبيرة حول استراتيجية “الأكبر هو الأفضل”.
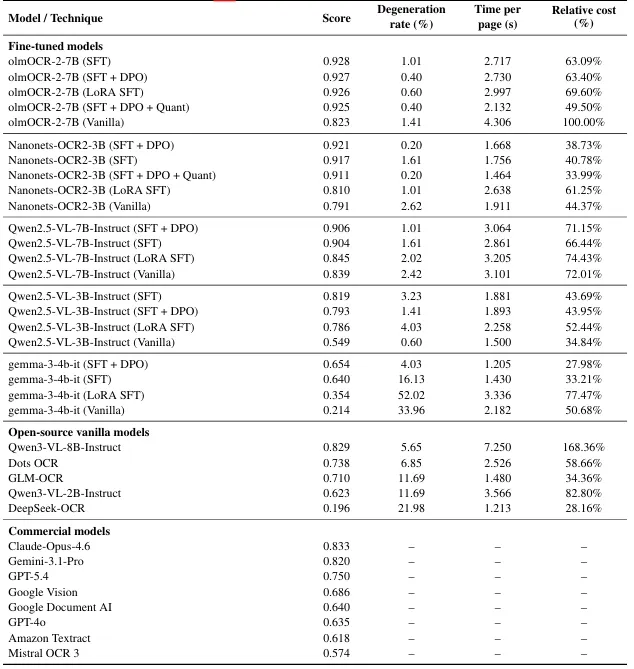
المعيار المستخدم كان استخراج النصوص من الوثائق البرتغالية البرازيلية – وثائق مطبوعة ومكتوبة بخط اليد وسجلات قانونية وإدارية. ليس المعيار هو النقطة المهمة، بل المقارنات التي أجروها والطريقة المنهجية في القياس.
- التفوق في الجودة بفارق حاسم: النموذج المتخصص DharmaOCR-3B حقق نتيجة 0.911 على المعيار المركب الذي يجمع بين مطابقة المسافة التحريرية وتداخل n-gram. Claude Opus 4.6 جاء في المركز الثاني بـ 0.833، يليه Gemini 3.1 Pro بـ 0.820، وGPT-5.4 بـ 0.750، وGoogle Vision بـ 0.686، وGoogle Document AI بـ 0.640، وGPT-4o بـ 0.635، وAmazon Textract بـ 0.618، وMistral OCR 3 بـ 0.574.
- انخفاض التكلفة بمعامل 52: تكلفة تشغيل النموذج المتخصص كانت أقل بحوالي 52 مرة لكل مليون صفحة من Claude Opus 4.6، وفقاً للحسابات التي تقارن تكاليف البنية التحتية للاستنتاج مع أسعار API المنشورة. منحنى الكفاءة يضع النموذج المتخصص في الزاوية العلوية اليسرى من الرسم البياني، مع النماذج التجارية في الأسفل واليمين.
- أقل معدل تدهور نصي في الإنتاج: النموذج سجل 0.20% فقط في معيار تدهور النص – وهو مقياس يقيس تكرار دخول النموذج في حلقات تعزيز ذاتي تؤدي لمخرجات غير قابلة للاستخدام. النموذج المتخصص الأقرب سجل 0.40%، بينما النماذج مفتوحة المصدر الأكبر والأعم سجلت معدلات أعلى. النماذج التجارية لم يتم قياسها مباشرة على هذا المعيار.
هذه النتائج الثلاث – الجودة والتكلفة والاستقرار، كلها يقودها النموذج المتخصص بـ 3 مليارات معامل – تشكل الدليل التجريبي الأقوى حتى الآن على أن المسافة من المهمة المطلوبة قد تكون المتغير الحاسم في الأداء، وليس حجم النموذج.
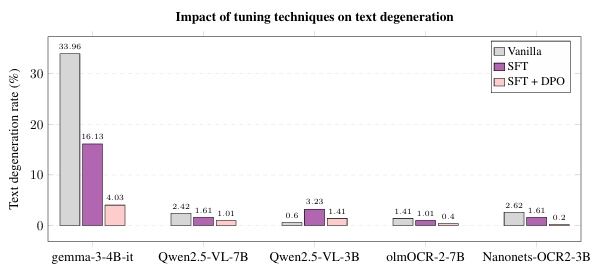
السبب وراء هذا التفوق أعمق من مجرد تحسين الأداء. نموذج بـ 3 مليارات معامل مركز على مهمة النشر سيتفوق غالباً على نموذج أكبر بكثير لكن معاملاته موزعة على مواد لن تلمسها المهمة أبداً – لغات أخرى، مجموعات نصوص أخرى، نطاقات أخرى. لكن البحث يذهب أبعد من هذا الفهم البديهي.
المتغير الحاسم ليس فقط كيفية توزيع المعاملات، بل كيف تم تحريك تاريخ تدريب النموذج نحو المهمة المطلوبة. في التجارب المُبلغ عنها، هذا المتغير تنبأ بالأداء النسبي بشكل أكثر موثوقية من أي متغير آخر تم اختباره – بما في ذلك عدد المعاملات.
الدليل على ذلك في المقارنات المباشرة. النموذج Nanonets-OCR2-3B – المتخصص مسبقاً في OCR العام قبل بدء البحث – خضع للتدريب الإشرافي المضبوط وتحسين التفضيل المباشر ووصل لـ 0.921 مع معدل تدهور 0.20%. نموذج عام بنفس البنية Qwen2.5-VL-3B خضع لنفس الإجراء ووصل لـ 0.793 مع معدل تدهور 1.41%. نفس البنية، نفس التدريب، نتيجة مختلفة. المتغير كان المسافة التي سافرها النموذج نحو المهمة قبل بدء الإجراء.
هذا النمط يتكرر عبر الأحجام المختلفة. على مستوى 7 مليارات معامل: أفضل نموذج مضبوط مشتق من Qwen2.5-VL-7B-Instruct – بداية عامة – وصل لـ 0.906 مع معدل تدهور 1.01%. نفس التدريب مطبق على olmOCR-2-7B – متخصص مسبقاً في OCR العام – وصل لـ 0.927 مع معدل تدهور 0.40%. المكسب في الجودة كان حوالي 2.3%؛ معدل التدهور انخفض بحوالي النصف.
هذا يكشف أن التخصص ليس حالة ثنائية يملكها النموذج أو يفتقدها، بل هرمية يمكن تسلقها خطوة بخطوة. النموذج العام في القاعدة؛ المتخصص في النطاق العام (مدرب على الفئة الأوسع من العمل) فوقه؛ المتخصص في النطاق المحدد (مدرب على العمل المحدد الذي سيتم نشره فيه) في الأعلى. نفس التدريب اللاحق ينتج نتائج مختلفة حسب الخطوة التي يبدأ منها النموذج.
على المستوى الاستراتيجي، هذا البحث يطرح تساؤلات جوهرية حول اقتصاديات الذكاء الاصطناعي. إذا كانت النماذج الصغيرة المتخصصة تستطيع تفوق النماذج الضخمة في مهام محددة بتكلفة أقل بشكل جذري، فما قيمة الاستثمار في النماذج العملاقة للاستخدامات المتخصصة؟ بالنسبة للمطورين والمؤسسات، السؤال الصحيح لم يعد “ما هو النموذج الأكبر المتاح؟” بل “ما هو النموذج الأقرب لمهمتي المحددة؟”
النتائج لا تدعي التعميم على كل أعباء العمل في الذكاء الاصطناعي للمؤسسات، لكنها تثبت بقوة أن افتراض “الأكبر هو الأفضل” قد لا يكون صالحاً عندما تصبح المواءمة التوزيعية للمهمة هي المتغير المهيمن. هذا يمكن أن يعيد تشكيل كيف نفكر في شراء واستراتيجية نشر الذكاء الاصطناعي بالكامل.