بقلم: نور | محررة الأبحاث والدراسات · صوت تحريري بإشراف بشري
47% فقط – هذا أفضل ما استطاع Claude Opus 4.7 تحقيقه في أول معيار حقيقي لقياس قدرة نماذج الذكاء الاصطناعي على حل مشاكل تقنية المعلومات في البيئات المؤسسية، وفقاً لمعيار ITBench-AA الذي أطلقته Artificial Analysis بالشراكة مع IBM Research.
يضع المعيار النماذج أمام 59 مهمة لهندسة موثوقية المواقع (SRE) تحاكي السيناريوهات التي يواجهها مهندسو الأنظمة يومياً: تشخيص أعطال Kubernetes عبر قراءة آلاف الأسطر من السجلات، تتبع التبعيات المعقدة بين الخدمات المترابطة، وتحديد السبب الجذري الحقيقي من بين عشرات المؤشرات المضللة. النتيجة؟ حتى أقوى النماذج تعثرت في مهام يحلها مهندس متوسط الخبرة.
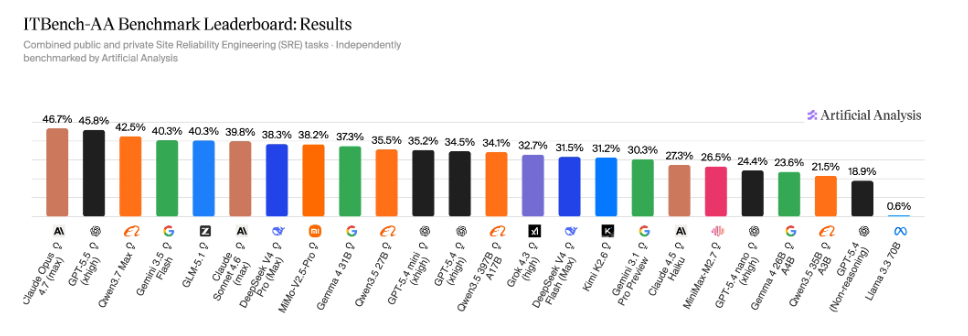
تفصل نقطة واحدة فقط بين المراكز الثلاثة الأولى: GPT-5.5 (xhigh) بـ46% وQwen3.7 Max بـ42%، بينما يقبع Gemini 3.1 Pro Preview في القاع بـ30% رغم استخدامه 83 محاولة بمعدل – أكثر من ضعفي عدد المحاولات التي احتاجها منافسوه الأفضل أداءً.
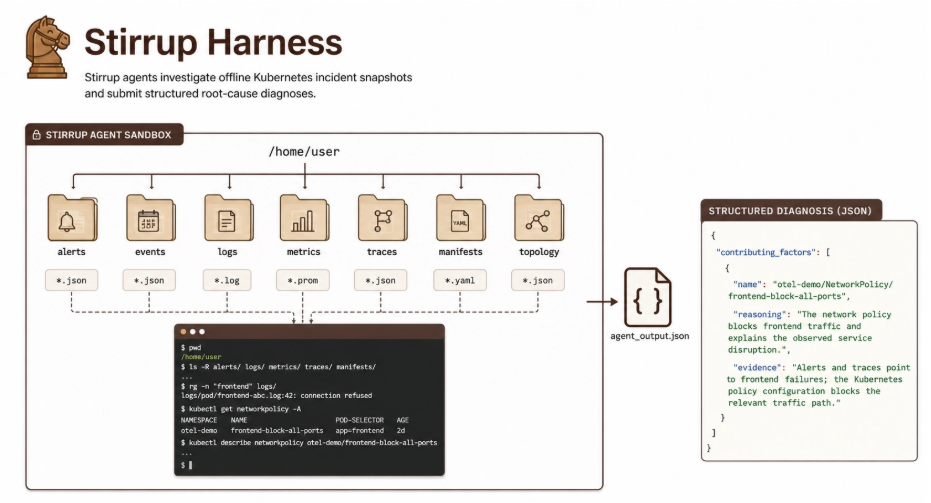
طور فريق IBM Research المعيار اعتماداً على خبرة الشركة الممتدة عقوداً في عمليات تقنية المعلومات المؤسسية. كل مهمة تمثل حادثة حقيقية: نقص حصص الموارد، فشل عمليات النشر، استنزاف مجمعات الاتصال، تقسيمات الشبكة، وحتى أعطال مقحمة عبر chaos engineering. النماذج تحصل على لقطة كاملة من النظام المتعطل – تنبيهات، أحداث، تتبعات، مقاييس، سجلات، وطوبولوجيا التطبيق – ويجب عليها تحديد الحد الأدنى من كيانات Kubernetes المسؤولة عن الحادثة.
في مهمة نموذجية، يواجه النموذج فشلاً في واجهة التطبيق الأمامية. يبدأ بفحص التنبيهات لتحديد نافزة زمنية الحادثة، ثم يحلل التتبعات والسجلات لتضييق النطاق على حركة مرور Frontend. طوبولوجيا الخدمات تكشف الخدمات المتأثرة، وفحص ملفات Kubernetes النهائي يفضح الجاني: سياسة شبكة تحجب جميع منافذ Frontend. الإجابة الصحيحة: otel-demo/NetworkPolicy/frontend-block-all-ports.
لكن الأداء الضعيف ليس القصة الوحيدة. النماذج المفتوحة تكتب فصلاً جديداً في معادلة التكلفة والجدوى الاقتصادية. GLM-5.1 (Reasoning) يتصدر النماذج مفتوحة الأوزان بـ40% مقابل 1.23 دولار للمهمة، مطابقاً أداء Gemini 3.5 Flash (high) الذي يكلف 1.70 دولار. الأكثر إثارة للاهتمام: Gemma 4 31B (Reasoning) يحقق 37% بـ0.14 دولار فقط، متفوقاً على Gemini 3.1 Pro Preview الذي يكلف 2.23 دولار ويحقق 30% فحسب.
في المقابل، Claude Opus 4.7 (Adaptive Reasoning, Max Effort) يدفع ضريبة التصدر باهظة: 5.38 دولار للمهمة الواحدة مقابل تفوق ضئيل بـ47%. للمؤسسات التي تتعامل مع مئات أو آلاف الحوادث شهرياً، هذا الفرق في التكلفة قد يكون حاسماً في قرارات التبني.
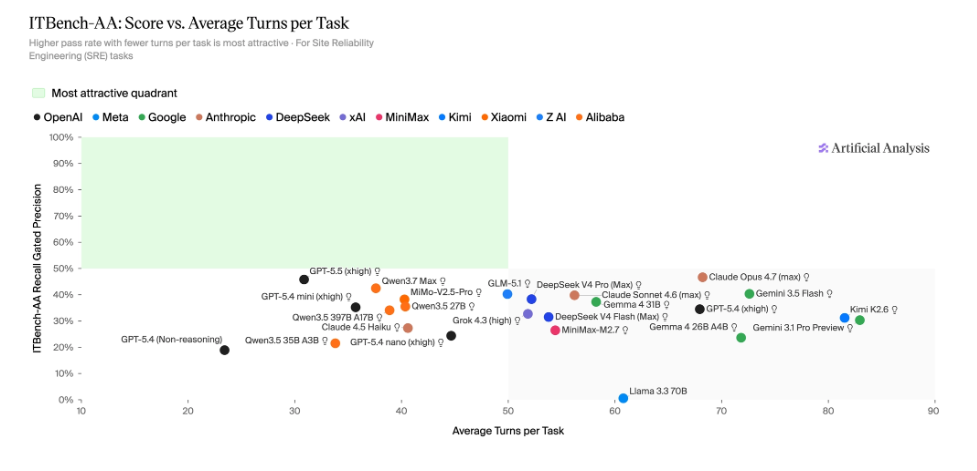
يكشف المعيار عن مفارقة مثيرة: الإفراط في التحقيق يضر أكثر مما ينفع. النماذج التي تستخدم محاولات أكثر لا تحقق بالضرورة نتائج أفضل، بل غالباً ما تسقط في فخ تحديد “إيجابيات زائفة” – آليات upstream أو أعراض مصاحبة تبدو مترابطة لكنها ليست السبب الجذري. نظام التسجيل “recall-gated precision” قاسٍ: إما أن تحدد كل الأسباب الجذرية الحقيقية أو تحصل على صفر، وإذا نجحت في ذلك تحصل على نقاط تساوي دقتك – نسبة الكيانات الصحيحة من إجمالي ما حددته.
يستخدم المعيار حزمة أدوات Stirrup مفتوحة المصدر كبيئة تنفيذ موحدة، مما يضمن مقارنة عادلة بين النماذج. كل نموذج يحصل على وصول للصدفة ونظام ملفات معزول يحتوي على السجلات واللقطات ذات الصلة، مع سقف 100 محاولة لكل مهمة و3 تكرارات. النتيجة النهائية هي متوسط الأداء عبر 59 مهمة × 3 تكرارات باستخدام متوسط الدقة عند الاستدعاء الكامل.
هذه ليست مجرد أرقام على ورق – إنها مرآة لواقع صناعة تقنية المعلومات. النماذج التي تحصل على علامات عالية في الاختبارات الأكاديمية تتعثر أمام التعقيدات الحقيقية للبنية التحتية الإنتاجية. المعيار سيتوسع تدريجياً ليشمل مهام العمليات المالية (FinOps) ومهام مدير أمن المعلومات (CISO)، مما قد يعيد تشكيل معايير تقييم قدرات الذكاء الاصطناعي في البيئات المؤسسية. الرسالة واضحة: النماذج الذكية ما زالت بحاجة لتعلم الكثير قبل أن تستطيع استبدال خبرة المهندسين البشريين في المهام الحرجة.







