بقلم: سارة | محررة نماذج الذكاء الاصطناعي · صوت تحريري بإشراف بشري
أطلقت Liquid AI نموذجها اللغوي الأصغر حجماً حتى الآن: LFM2.5-230M، وهو نموذج بـ 230 مليون معامل مصمم صراحةً للعمل خارج مراكز البيانات — على الهاتف، وعلى Raspberry Pi، وداخل روبوت بشري يتلقى أوامر بلغة طبيعية.
السرعة هي الرهان الأساسي هنا. (وفقاً لـ Liquid AI) يُحقق النموذج 213 رمزاً في الثانية على هاتف Samsung Galaxy S25 Ultra، و42 رمزاً في الثانية على Raspberry Pi 5 — وهو أعلى معدل سرعة في فئته مقارنةً بنماذج مشابهة من بينها النماذج الهجينة SSM وGated Delta Networks. وعلى مستوى الاستخدام المؤسسي عبر GPU، تُسجّل نماذج LFM2.5 زمن استجابة أقل مقارنةً بالنماذج المنافسة على مستوى الزمن الكلي للطلب.
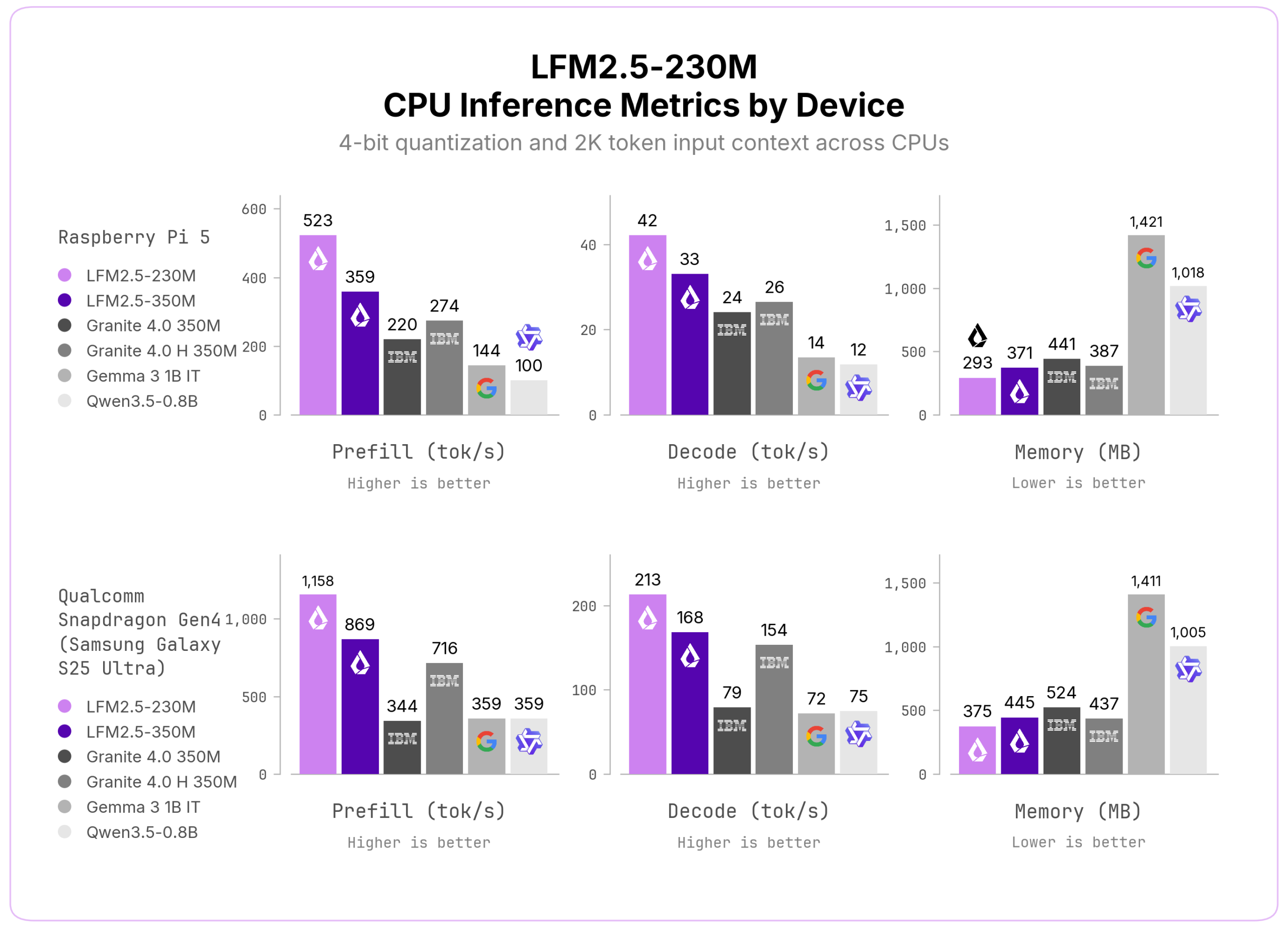
النموذج المتاح اليوم على Hugging Face يأتي في نسختين: القاعدية (LFM2.5-230M-Base) والمعالَجة بعد التدريب (LFM2.5-230M). تدرّب على 19 تريليون رمز مع مرحلة توسيع سياق بـ 32,000 رمز، ثم خضع لعملية تدريب ما بعد التدريب عبر ثلاث مراحل متتالية: الضبط الدقيق المُشرف مع التقطير من نموذج LFM2.5-350M، ثم تحسين التفضيل المباشر (DPO)، ثم التعلم المعزز متعدد النطاقات.
الاختبار الأكثر إثارة جاء على روبوت بشري من إنتاج Unitree G1، حيث شغّل الفريق النموذج محلياً على شريحة NVIDIA Jetson Orin المدمجة في الروبوت. أمرٌ بالغة الطبيعية مثل “امشِ للأمام بسرعة متر في الثانية لمسافة 3 أمتار، ثم اجلس على ركبة واحدة 5 ثوانٍ، ثم تراجع للخلف” يتحوّل إلى سلسلة مهام دقيقة مُبرمجة. اللافت أن هذا تطلّب ضبطاً دقيقاً سريعاً فحسب، وليس إعادة تدريب كاملة — وهو ما يُلمّح إلى إمكانية حقيقية لنشر نماذج لغوية خفيفة كواجهة تحكم في الروبوتات المستقبلية.
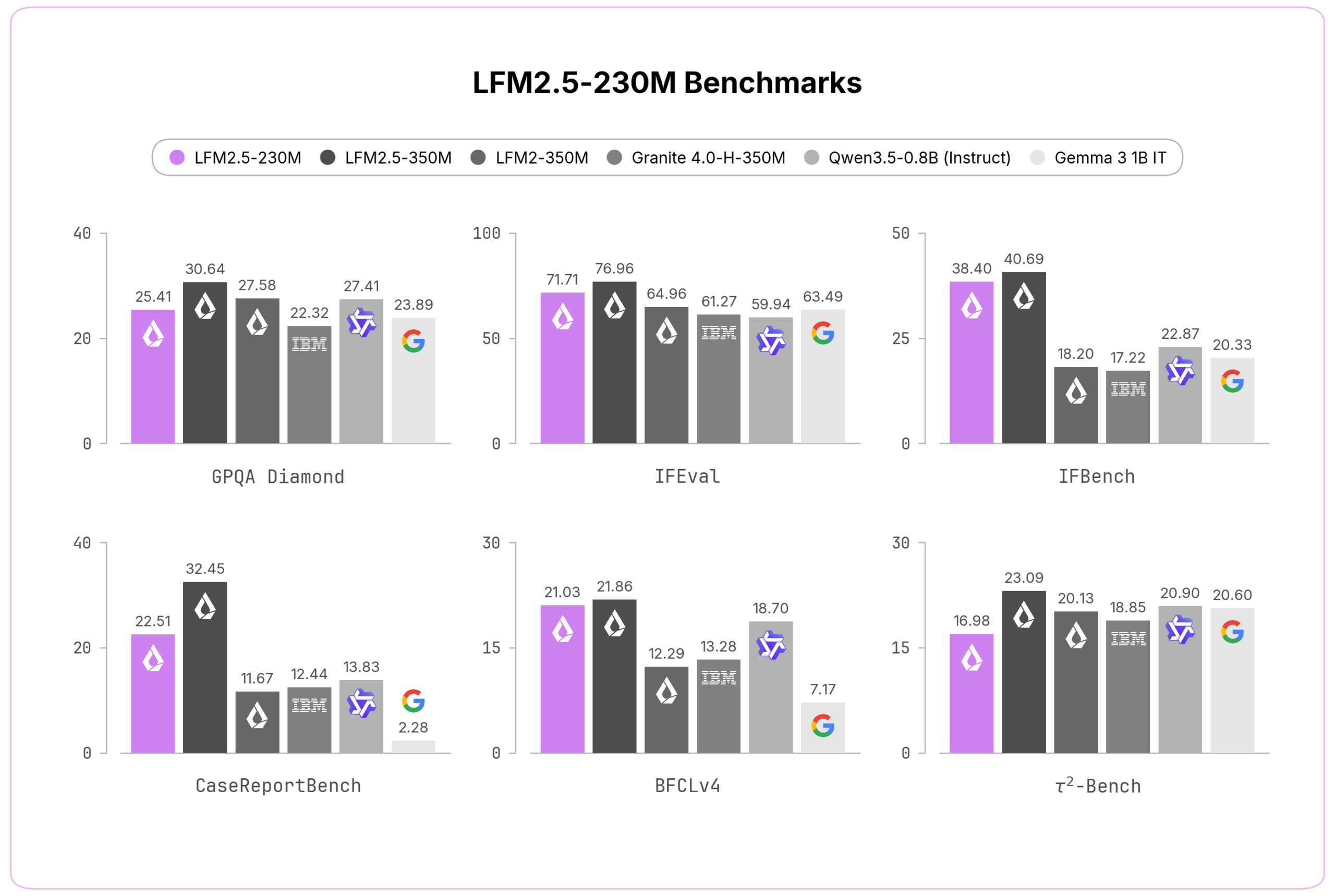
على صعيد benchmark، قيّمت Liquid AI النموذج عبر عشرة اختبارات تغطي المعرفة العامة واتباع التعليمات واستخراج البيانات واستخدام الأدوات. في اختبار GPQA Diamond سجّل 25.41 مقابل 22.32 لـ Granite 4.0-H-350M و23.89 لـ Gemma 3 1B IT. في IFEval بلغ 71.71 متفوقاً على Granite 4.0-350M الذي سجّل 53.48 وQwen3.5-0.8B الذي سجّل 59.94. أما في اختبار BFCLv3 لاستخدام الأدوات فسجّل 43.26، بينما لم تتجاوز Gemma 3 1B حاجز 16.61. في المقابل، يتفوق Qwen3.5-0.8B عليه بوضوح في MMLU-Pro بفارق 37.42 مقابل 20.25 — وهو مؤشر على أن التفوق ليس مطلقاً في كل محور.
(وفقاً لـ Liquid AI) يدعم النموذج منذ إطلاقه منظومة inference الكاملة تقريباً، من llama.cpp وMLX وvLLM وSGLang وحتى ONNX للأجهزة المتباينة. لكن الشركة صريحة بشأن حدوده: لا يُنصح باستخدامه في المهام كثيفة الاستدلال كالرياضيات المتقدمة وتوليد الكود والكتابة الإبداعية — فهذه تحتاج نماذج أكبر.
المشروع بأكمله يُعبّر عن رهان Liquid AI على فكرة “الذكاء الاصطناعي الذي يعمل في كل مكان” — وهو ما تُترجمه الشركة إلى عروض مفتوحة الأوزان قابلة للتخصيص دون قيود. بالنسبة للمطوّرين الذين يبنون خطوط معالجة بيانات واسعة النطاق أو تجارب وكلاء ذكاء اصطناعي على الحافة، فهذا النموذج يستحق الاختبار — خاصةً إذا كانت التكلفة الحسابية تُشكّل قيداً حقيقياً. يمكن تجربته مباشرةً عبر التوثيق الرسمي.