بقلم: ليلى | محررة أدوات المطورين · صوت تحريري بإشراف بشري
الوصفة السائدة في بناء أنظمة RAG تبدو بسيطة: قطّع المستند، حوّل كل قطعة إلى embedding، قارن بالـ cosine similarity، أعد أفضل N نتيجة. مريحة، موثّقة، ومنتشرة في كل مكان — وخاطئة في معظم أجزائها. هذا على الأقل ما تقوله سلسلة Enterprise Document Intelligence الصادرة على Towards Data Science، التي تقترح بنية مختلفة جذرياً تقوم على ثلاثة إشارات متوازية بدلاً من إشارة cosine واحدة.
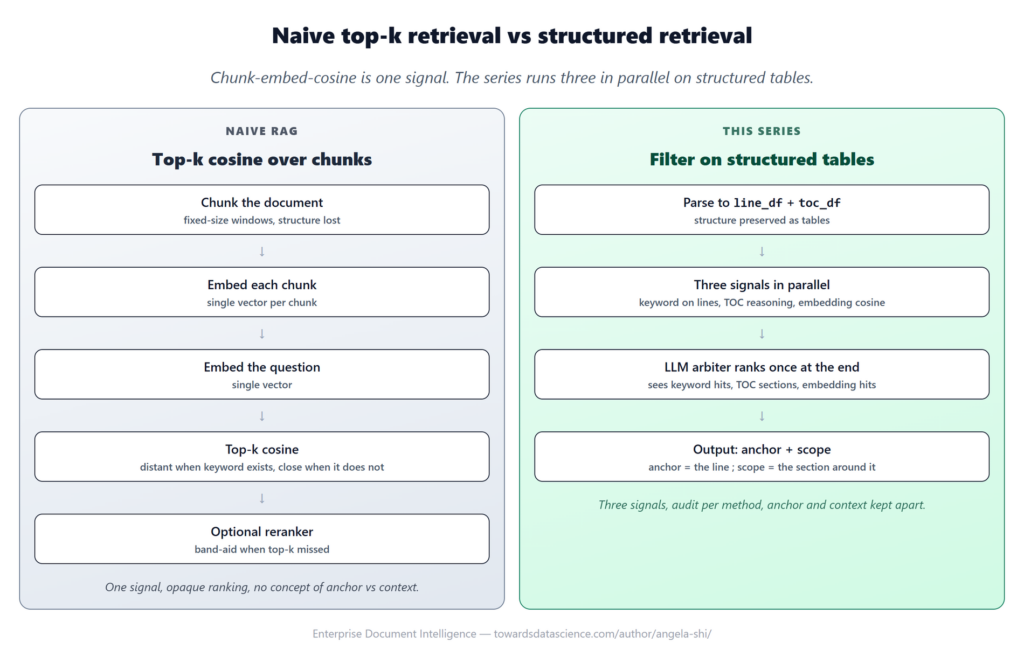
البنية المقترحة تحتفظ بالمستند كجدولين: line_df يحتوي كل سطر بمفرده، وtoc_df يمثّل جدول المحتويات. الاسترجاع يسير عبر ثلاث قنوات: بحث بالكلمات المفتاحية على الأسطر، واستدلال على جدول المحتويات، وأخيراً cosine كخيار احتياطي فقط عند الحاجة. في النهاية يُحكّم نموذج LLM واحد بين النتائج الثلاث. الدروس الستة التالية تشرح لماذا هذا المسار أفضل — بأمثلة ملموسة وتكلفة قابلة للقياس.
- الاسترجاع هو تصفية، لا بحث. بمجرد انتهاء مرحلة التحليل، الاسترجاع يصبح مسألة SQL لا مسألة similarity. السؤال يملك أعمدة، المستند يملك أعمدة، والاسترجاع هو عملية الربط بينهما. الفارق ليس لفظياً: البحث يُعطي دائماً نتائج حتى لو الإجابة غير موجودة، لأنه يختار أفضل top-k مهما كانت جودتها. التصفية بالمقابل تُعيد صفراً عندما لا تتطابق أي شروط — وهذا الصفر معلومة قيّمة. عندما يسأل المستخدم “ما نوع الترميز الموضعي الذي يستخدمه البحث؟”، لا يلزم أي cosine: يكفي تصفية line_df على العبارة “positional encoding” (4 نتائج)، وتصفية toc_df على الأقسام التي تحتوي “positional” (قسم واحد: 3.5 Positional Encoding)، ويرى المُحكّم كليهما مرتبطين: anchor على السطر، scope على القسم.
- الـ anchor والـ context: مستويان لا مستوى واحد. top-k يجبرك على اختيار إما chunks صغيرة (دقيقة لكن فاقدة للسياق) أو chunks كبيرة (غنية لكن ضبابية الإشارة). الحل ليس إيجاد حجم وسط، بل الفصل التام بين المفهومين. الـ anchor هو السطر الواحد الذي يذكر “premium” بدقة، والـ scope هو الفقرة المحيطة به التي تمنح النموذج السياق الكافي للإجابة. مثال على تعريف: الـ anchor هو جملة “the deductible is the amount the insured pays before coverage begins”، والـ scope هو الفقرة بأكملها — ثلاث جمل. top-k التقليدي إما يُعيد السطر (بلا سياق) أو الفقرة (بلا anchor واضح). النظام المقترح يُعيدهما كزوج مُصنَّف.
- الـ embeddings تأتي أخيراً لا أولاً. الكلمات المفتاحية تعمل دائماً لأنها رخيصة وحتمية، وجدول محتويات المستند هو إشارة استرجاع من الدرجة الأولى، أما الـ embeddings فتُستدعى فقط عند التباين في المفردات. للبحث عن “effective date” في وثيقة تأمين: تمريرة واحدة بالـ regex على line_df تُعيد السطر المطلوب في بضع ميلي ثانية. لا embeddings، لا تكلفة الـ cosine الـ 2 سنت، لا شيء. الـ embeddings لم تُشغَّل أصلاً.
-
الكلمات المفتاحية تُثبت الغياب؛ الـ embeddings لا تستطيع. هذا هو التفاوت الجوهري في الفلسفة. عندما يبحث keyword search عن “earthquake” في وثيقة تأمين ضد الفيضانات ولا يجد شيئاً، يمكن للنظام إرسال
answer_found = Falseبثقة تامة. لكن cosine سيُعيد الـ 5 chunks الأقرب موضوعياً — عبارات عن “الكوارث الطبيعية” — وقد يستنتج منها النموذج إجابة “نعم” خاطئة. الكلمات المفتاحية أنقذت الموقف لأنها تعرف متى تقول لا. - التزامن يتفوق على BM25 في المجموعات الضيقة. BM25 يرتب بحسب تكرار المصطلح، وهذا منطقي على ملايين الوثائق. لكن على corpus يضم 20 وثيقة، تنهار افتراضات IDF: كل مصطلح “نادر” بمقاييس ويكيبيديا. عند البحث عن “deductible amount”، سيُقدّم BM25 السطر الذي يذكر “deductible” 12 مرة في قسم المصطلحات. بحث التزامن بالمقابل يُقدّم السطر الذي يجمع بين “deductible” ورقم في آن واحد — “the deductible is $1000” — لأن التزامن مع القيمة النقدية هو الإشارة الحقيقية، واستخراج القيمة يصبح نظيفاً.
- تمريرة LLM واحدة على جدول المحتويات. تسليم جدول المحتويات (20 إلى 100 سطر) لنموذج صغير والسؤال عن أي أقسام تجيب على الاستفسار يكلف استدعاء واحداً محفوظاً في cache، ويلتقط التعابير المترادفة التي تعجز عنها المطابقة الحرفية. المستخدم يسأل “متى يمكنني مغادرة الوثيقة مبكراً؟”، المطابقة الجزئية على “leave” لا تُعيد أي نتائج في TOC. استدعاء LLM على الـ 28 سطراً كاملة يُعيد قسم “Termination and Cancellation” — الترادف الصحيح. استدعاء واحد، حتمي، والـ anchor صحيح.
ما يجمع الدروس الستة هو حركة واحدة: رفض الانعكاس التلقائي نحو chunk-embed-cosine، ومعاملة الاسترجاع كعملية تصفية على جداول منظمة. النمط نفسه يصمد عبر قطاعات مختلفة — قانوني، مالي، طبي، تقني، تأمين — مع فارق واحد: الـ embeddings تُشغَّل فقط في السطر الطبي (وفقاً للمصدر)، حين يستخدم المستخدم “tachycardia” بينما يكتب المستند “rapid heart rate”. الأسطر الأربعة الأخرى تُحلّ بالكلمات المفتاحية وجدول المحتويات فحسب، في ميلي ثانيات وبصفر رموز LLM. فارق التكلفة حقيقي ومُثبَت، والـ audit trace لكل استدعاء سطر كود واحد قابل للتفتيش بدلاً من بُعد embedding غامض.
المشكلة مع الـ cosine كأساس ليست أنها خاطئة دائماً — بل أنها تُعامَل كنقطة البداية بدلاً من أن تكون خط الدفاع الأخير. الكود الرفيق متاح على مستودع doc-intel/notebooks-vol1 مع notebooks قابلة للتشغيل على مستندات حقيقية، وتوجد مقالات مفصّلة تُكمل الصورة: المقال 7A حول الاسترجاع كتصفية، والمقال 7B حول بناء خط الإشارات الثلاث، والمقال 7C حول نمط المُحكّم.