بقلم: نور | محررة الأبحاث والدراسات · صوت تحريري بإشراف بشري
خمس سنوات من عمل عالم البيانات مضغوطة في استدعاء واحد — هذا ما يعد به TabFM، النموذج الأساسي الجديد من جوجل ريسيرش الذي يُعيد تأطير التنبؤ بالبيانات الجدولية كمسألة تعلم في السياق، لا كمهمة تدريب تقليدية. النموذج متاح الآن على Hugging Face وGitHub.
البيانات الجدولية هي العمود الفقري لمعظم تطبيقات التعلم الآلي في المؤسسات، من التنبؤ بمغادرة العملاء إلى اكتشاف الاحتيال المالي. غير أن نشر نماذج مثل XGBoost أو Random Forests كان يعني حتى الأمس تحسين hyperparameters لساعات، وهندسة ميزات متخصصة، وإعادة التدريب الكامل مع كل جدول جديد. TabFM يقطع هذه الحلقة كلياً.
الفكرة الجوهرية مستوحاة مباشرة من نجاح LLMs في التعلم في السياق: بدلاً من تحديث أوزان النموذج لكل مجموعة بيانات جديدة، يأخذ TabFM الجدول كاملاً — بياناته التاريخية والصفوف المُستهدفة معاً — ويُدخله في موجّه واحد. النموذج يستنتج العلاقات بين الأعمدة والصفوف في وقت الاستدلال مباشرة، دون أي تحديث للأوزان.
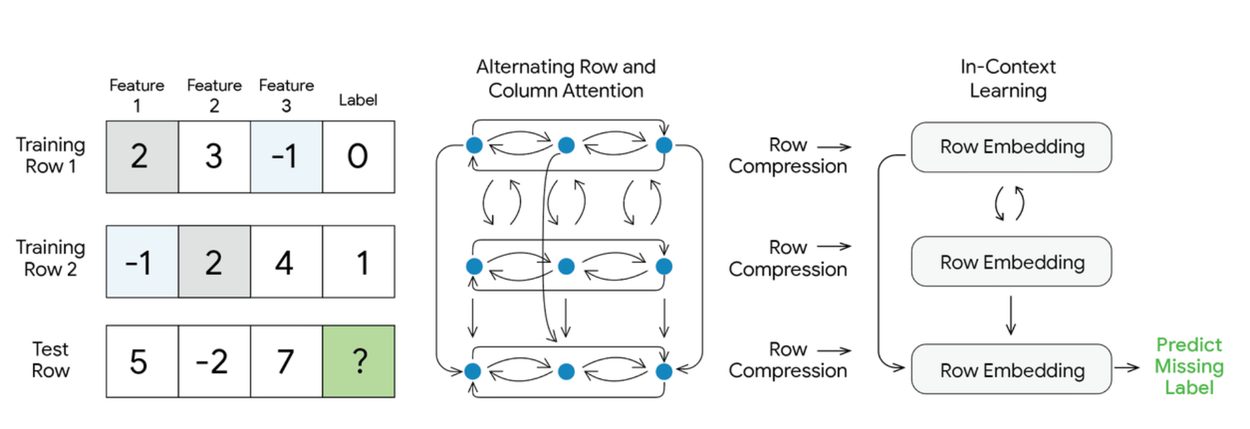
التحدي التقني الجوهري هو أن الجداول ليست نصاً. نماذج اللغة تعالج تسلسلاً أحادي البُعد ومرتباً، بينما الجدول ثنائي الأبعاد وعديم الترتيب: تبديل صفين أو عمودين لا يغير المعنى. لمعالجة هذا، بنى الفريق معمارية هجينة تجمع بين مزايا TabPFN وTabICL في ثلاث آليات متسلسلة:
- الانتباه المتناوب على الصفوف والأعمدة: يعالج الجدول الخام عبر طبقات انتباه متعددة تنتقل بالتناوب بين الأعمدة (الميزات) والصفوف (الأمثلة). هذا يبني تمثيلات غنية تلتقط التفاعلات المعقدة بين الميزات، وهو ما كان يستلزم تقليدياً هندسة ميزات يدوية مضنية.
- ضغط الصفوف: بعد التسييق المتقاطع، تُضغط المعلومات الغنية لكل صف في متجه كثيف واحد. هذه الخطوة هي التي تجعل الحساب قابلاً للتوسع مع الجداول الكبيرة.
- التعلم في السياق (ICL): يعمل Transformer مخصص على تسلسل متجهات الصفوف المضغوطة. بدلاً من معالجة الشبكة الخام كاملة، يُجري الانتباه على هذه التمثيلات المضغوطة، مما يخفض تكلفة الحساب بشكل جذري ويُبقي التنبؤ فعالاً حتى مع مجموعات البيانات الكبيرة.
أما مسألة بيانات التدريب، فكانت عائقاً حقيقياً: الجداول الصناعية عالية الجودة نادرة في الفضاء مفتوح المصدر، وغالباً تحتوي على معلومات خاصة أو حساسة. الحل الذي اعتمده الفريق هو التدريب بالكامل على مئات الملايين من مجموعات البيانات الاصطناعية، تُولَّد ديناميكياً باستخدام النماذج السببية البنيوية (SCMs) التي تدمج دوال عشوائية متنوعة لتحاكي طيفاً واسعاً من توزيعات البيانات الواقعية.
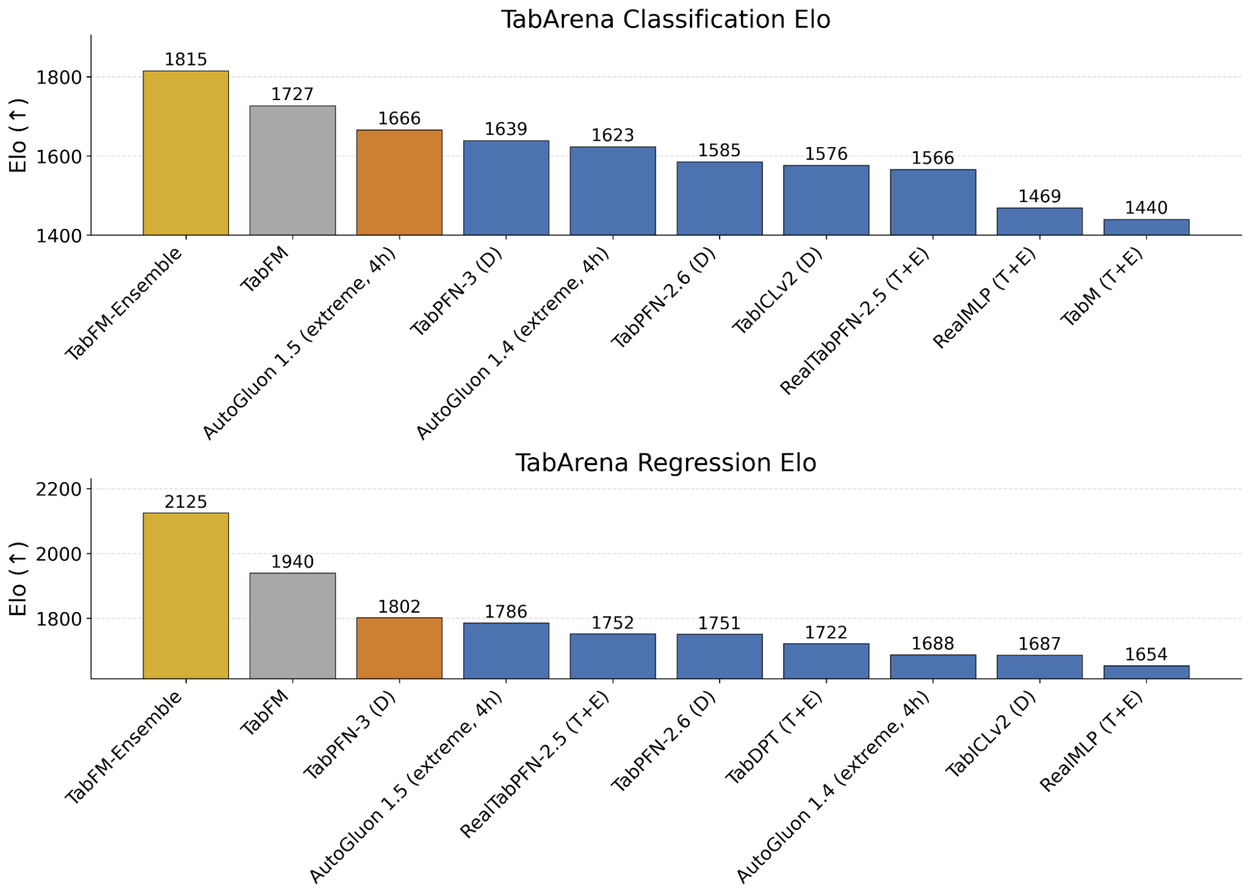
النتائج اختُبرت على TabArena، نظام معياري حي يحسب تقييمات Elo بناءً على معدلات الفوز في المقارنات الثنائية. (وفقاً لـ Google Research) شملت التقييمات 38 مجموعة بيانات تصنيف و13 مجموعة بيانات انحدار، تتراوح أحجامها بين 700 و150,000 عينة. اختُبر النموذج في إعدادين متمايزين: الأول TabFM الخروج من الصندوق في تمرير أمامي واحد بدون ضبط، والثاني TabFM-Ensemble الذي يُضيف ميزات cross features وميزات SVD (تحليل القيم المفردة) مع حساب أوزان مجموعة من 32 نموذجاً باستخدام حل least squares غير السلبي، وبالنسبة للتصنيف يُضاف Platt scaling كخطوة معايرة إضافية. النتيجة: أداء يتجاوز باستمرار الخوارزميات الكلاسيكية الخاضعة للضبط المكثف.
الأهم عملياً هو القرار الذي أعلنه الفريق في نهاية الورقة: TabFM سيُدمج مباشرة في Google BigQuery، وخلال الأسابيع القادمة سيتمكن المستخدمون من تشغيل الانحدار والتصنيف المتقدمَين بأمر SQL واحد فقط: AI.PREDICT، دون الحاجة لأي خبرة في التعلم الآلي. هذا يعيد رسم خط الوصول إلى هذه القدرات بشكل كامل — شخص يعرف SQL يمكنه الآن الحصول على تنبؤات كانت تستلزم فريق علماء بيانات.
ما يلفت الانتباه في هذا الإصدار أنه يسير في الاتجاه نفسه الذي سلكته TimesFM مع بيانات السلاسل الزمنية، لكن مع تحدي أكبر: بيانات الجداول أكثر تنوعاً وأقل انتظاماً. الاختبار الحقيقي سيكون على الجداول الصناعية الخاصة ذات الأعمدة المئات والعلاقات المخفية — وهو ما لا تكشف عنه نتائج TabArena العامة بشكل كافٍ بعد.