بقلم: نور | محررة الأبحاث والدراسات · صوت تحريري بإشراف بشري
عندما يتحدث عميل بالإسبانية ثم يُكمل جملته بالإنجليزية، هل تفهم أنظمة التعرف على الكلام ما يقول؟ تساءلت ServiceNow AI عن هذا الأمر عندما سأل أحد عملائها عن أداء وكلائهم الصوتيين مع قاعدة عملاء تتبدل بين اللغات بشكل طبيعي، فقرروا بناء أول مقياس شامل لاختبار 7 نماذج رائدة في التعرف التلقائي على الكلام.
النتيجة؟ فروق جذرية في قدرة النماذج على التعامل مع ما يُسمى “التبديل اللغوي” (code-switching) — وهو التنقل الطبيعي بين لغتين حتى في منتصف الجملة الواحدة. أكثر من نصف سكان العالم يتحدثون بأكثر من لغة واحدة (وفقاً لـ ServiceNow AI)، ومع ذلك لم توجد أدوات قياس مناسبة لتقييم هذا الواقع في البيئات المؤسسية.
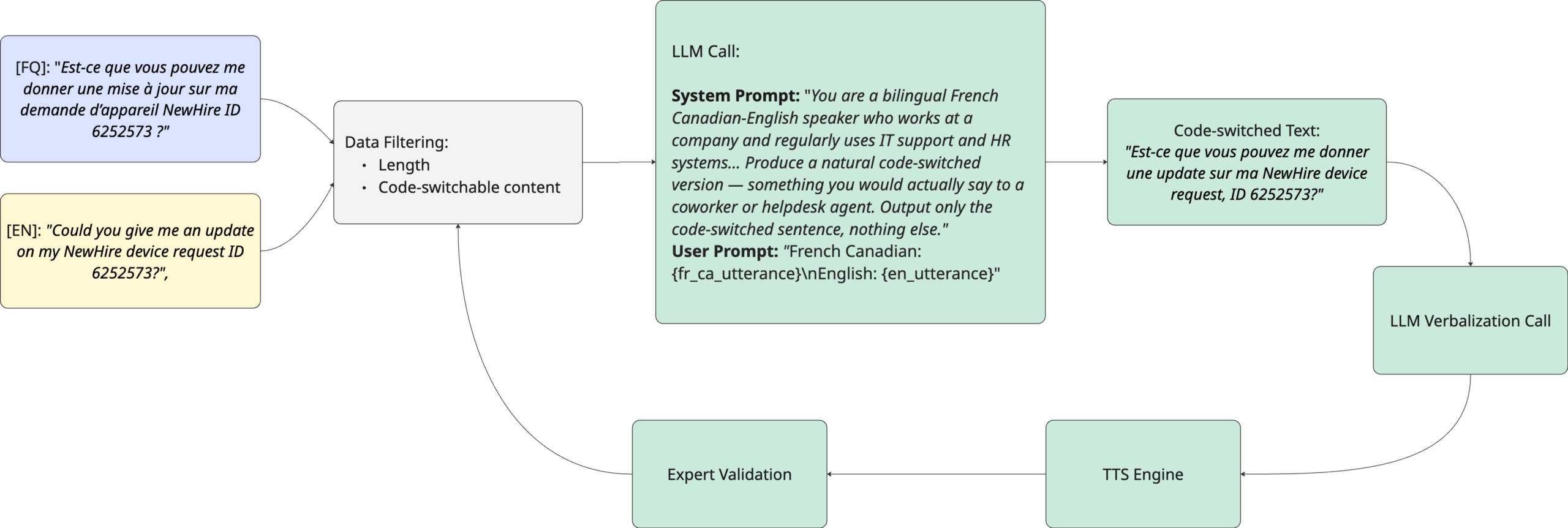
بنى الفريق مجموعة بيانات من سيناريوهات الموارد البشرية وإدارة خدمات تقنية المعلومات، تغطي أربعة أزواج لغوية: الإسبانية-الإنجليزية (259 تسجيلاً)، الفرنسية-الإنجليزية (298 تسجيلاً)، الفرنسية الكندية-الإنجليزية (188 تسجيلاً)، والألمانية-الإنجليزية (173 تسجيلاً). استُخدم GPT-5 لإنتاج النص المتبدل لغوياً، وElevenLabs Multilingual V2 لتوليد الصوت، مع مراجعة لغوية من متحدثين أصليين لكل لغة أساسية.
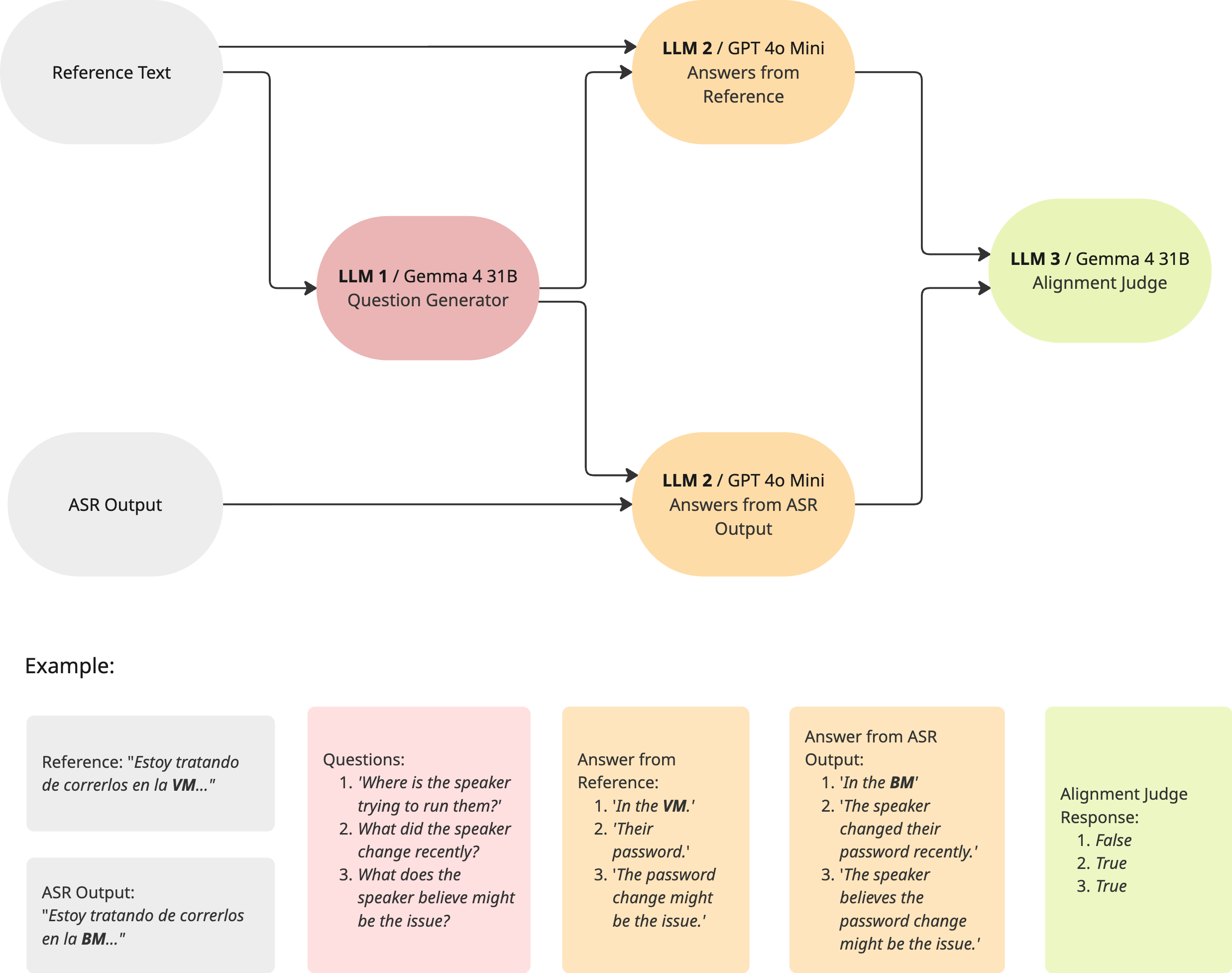
اعتمد المقياس على ثلاثة مؤشرات أداء: معدل خطأ الكلمات (WER) لقياس الدقة الحرفية، معدل الخطأ الدلالي (SWER) باستخدام Gemma-4-31B كحكم، ومعدل خطأ الإجابة (AER) الذي يختبر قدرة نموذج لغوي على الإجابة على ثلاثة أسئلة فهم من النسخة المُخرجة.
- ElevenLabs Scribe V2 يحقق أفضل أداء شامل: تصدر في معدل خطأ الكلمات عبر جميع الأزواج اللغوية مع تعادل مع AssemblyAI في الإسبانية-الإنجليزية، وحافظ على الصدارة في المقاييس الدلالية بدرجات SWER وAER منخفضة جداً.
- AssemblyAI Universal 3-Pro يحقق دقة نسخ عالية لكن يتراجع دلالياً: جاء أولاً أو ثانياً في WER عبر جميع الأزواج اللغوية، لكن Gemini 3 Flash تفوق عليه باستمرار في AER ودفعه للمرتبة الثالثة، مما يشير إلى أن أخطاءه تؤثر على الفهم أكثر.
- Google Gemini 3 Flash يبرز في الفهم رغم تراجع النسخ: احتل المرتبة الثالثة في WER لكنه تفوق على AssemblyAI في AER عبر كل الأزواج اللغوية، وهو انعكاس مباشر لطبيعته كنموذج لغوي صوتي كبير محسّن لفهم اللغة والاستدلال.
- الفئة الوسطى تتنوع بحسب اللغة: Deepgram Nova-3 وMistral Voxtral وNVIDIA Parakeet احتلوا المراتب الوسطى مع تفوق كل منهم في زوج لغوي واحد على الأقل — Parakeet كان الأضعف عموماً لكنه تفوق في الألمانية-الإنجليزية.
- OpenAI Whisper يواجه مشكلة هيكلية: سجل أسوأ أداء بمعدل خطأ من 0.16 إلى 0.61 في WER لأنه يترجم الكلام متعدد اللغات إلى الإنجليزية بدلاً من نسخه كما هو عند عدم تحديد معامل لغة صريح.
- تكلفة التبديل اللغوي تختلف بحسب قوة النموذج: النماذج الأقوى واجهت عقوبة صغيرة فقط مقارنة بخطوط الأساس أحادية اللغة، بينما تدهورت النماذج الأضعف بشكل كبير، مما يشير إلى أن التبديل اللغوي يكشف الفروق في المتانة أكثر من كونه يرفع الصعوبة بشكل موحد.
- عدد مرات التبديل ونسبة اللغة الثانوية تؤثران على الأخطاء: أظهر تحليل انحدار ثنائي الأجزاء أن زيادة عدد التبديلات في العبارة ومؤشر الخلط اللغوي (CMI) — نسبة كلمات اللغة الثانوية — يرفعان احتمالية حدوث أخطاء وحجمها عند حدوثها.
النتائج تكشف نمطاً هيكلياً مثيراً: التكلفة مقارنة بالإنجليزية (الأعمدة الخضراء) كانت دائماً أكبر من التكلفة مقارنة باللغة الثانية (الأعمدة الحمراء). هذا منطقي لأن خط الأساس أحادي اللغة الثانية أصعب من الإنجليزية لمعظم النماذج، فتصبح عقوبة التبديل أصغر عند قياسها مقارنة به.
استثناء واضح هو Whisper الذي أظهر أكبر تدهور مقارنة بالإنجليزية وصل إلى +0.85 في الألمانية-الإنجليزية، وكان النموذج الوحيد الذي أدى بشكل أفضل في الكلام متعدد اللغات من اللغة الثانية أحادية اللغة — نتيجة مباشرة لتحويله للترجمة بدلاً من النسخ.
أطلق الفريق مجموعة البيانات الكاملة وأداة التقييم AU-Harness للعموم، مما يفتح المجال لمقارنات مستقلة وتطوير نماذج محسّنة للبيئات متعددة اللغات. في عالم يزداد فيه الاعتماد على وكلاء الصوت لخدمة عملاء يتحدثون بلغات متعددة، هذا المقياس يسد فجوة حاسمة في تقييم الجاهزية التجارية الحقيقية لهذه التقنيات.







