كشفت إرشادات عملية عن طريقة مبسّطة لاستخدام Gemini من غوغل لإنشاء عروض تقديمية تلقائيًا بالاعتماد على الذكاء الاصطناعي، ما يوفّر الوقت والجهد على المستخدمين في إعداد الشرائح يدويًا.
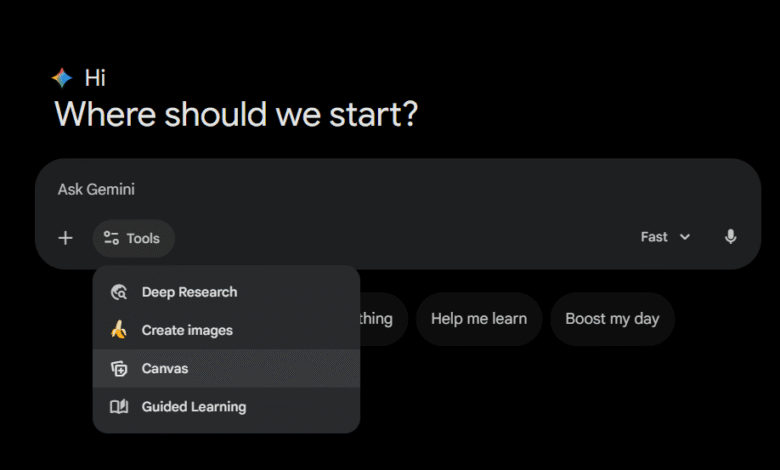
وتبدأ العملية بتسجيل الدخول إلى Gemini، ثم رفع المستند المراد تحويله إلى عرض تقديمي، سواء كان ملف PDF أو Word أو نصًا عاديًا. بعد رفع الملف، ينتقل المستخدم إلى قسم Tools ويختار أداة Canvas.
بعد ذلك، يكتب المستخدم مطالبة بسيطة مثل:
«أنشئ عرض شرائح تقديميًا من هذا المستند».
وخلال وقت قصير، يقوم Gemini بتحليل المحتوى، واستخلاص الأفكار الرئيسية، وتنظيمها في شرائح عرض جاهزة. وعند الانتهاء، يمكن للمستخدم الضغط على خيار Export to Slides لفتح العرض مباشرة داخل Google Slides.
وتتيح هذه الخطوة الأخيرة تعديل التصميم، وتحسين النصوص، وإضافة اللمسات النهائية يدويًا، ما يجعل الأداة مناسبة للعروض المهنية والتعليمية على حد سواء. ويُنظر إلى هذه الميزة كجزء من توجه أوسع نحو أتمتة المهام المكتبية باستخدام الذكاء الاصطناعي.
📌 الملخص:
Gemini يتيح تحويل المستندات إلى عروض تقديمية تلقائيًا عبر Canvas، مع إمكانية تصديرها مباشرة إلى Google Slides وتحريرها بسهولة.