بقلم: يوسف | محرر أدوات الذكاء الاصطناعي · صوت تحريري بإشراف بشري
تدفع Cursor حدود الترميز الذكي خطوة أخرى للأمام مع إطلاق Composer 2.5، النسخة المطورة من نموذجها للترميز المدعوم بالذكاء الاصطناعي. يستهدف هذا التحديث الكبير معالجة التحديات الحقيقية التي يواجهها المطورون في المشاريع المعقدة، خاصة في الحفاظ على جودة واتساق الكود عبر مراحل التطوير الطويلة.
القفزة التقنية الأبرز في النموذج الجديد تكمن في اعتماده على تصحيحات التعلم المعزز المستهدف التي تستخدم ردود فعل نصية محلية لتحقيق ضبط أكثر دقة. هذا التطور يسمح للنموذج بالتعلم من أخطائه بشكل متدرج أثناء تنفيذ المهام الطويلة، بدلاً من الاعتماد على تدريب عام فقط.
الاستثمار في البيانات التدريبية كان ضخماً أيضاً، حيث حصل Composer 2.5 على زيادة 25 ضعفاً في التدريب على المهام الاصطناعية مقارنة بالنسخة السابقة. هذا التوسع الهائل في البيانات التدريبية، مقترناً بتحسينات المعايرة السلوكية، يهدف لجعل النموذج أكثر قدرة على فهم التعليمات المعقدة والحفاظ على اتساق الترميز.
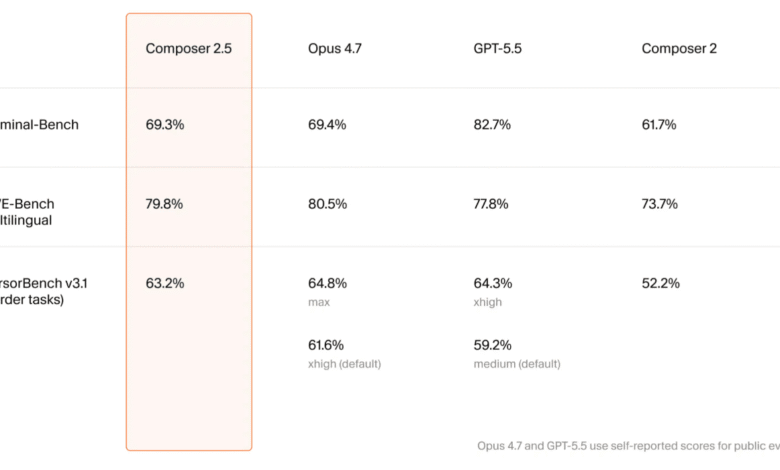
النتائج الأولية مبشرة بقوة، حيث تظهر اختبارات الأداء المبكرة تحسناً كبيراً في المهام البرمجية الممتدة واستدعاءات الأدوات مقارنة بـ Composer 2 والمساعدين المنافسين. الأهم من ذلك، تدّعي Cursor أن النموذج يحقق كفاءة تصل إلى 10 أضعاف أفضل من ناحية التكلفة – رقم يستحق المراقبة عن كثب من قبل الفرق التقنية التي تبحث عن حلول اقتصادية.
ما يثير الاهتمام حقاً هو فلسفة التطوير وراء هذا التحديث. بدلاً من السباق وراء السرعة فحسب، تركز Cursor على الموثوقية والاتساق في البيئات المعقدة – وهو توجه نحتاجه بشدة في عالم أدوات الذكاء الاصطناعي للبرمجة التي غالباً ما تفقد التماسك في المشاريع الكبيرة.
لكن التفاصيل المفقودة تثير تساؤلات مهمة. لا توضح Cursor آلية الوصول للنموذج، سواء كان متاحاً للمطورين الفرديين أم مقتصراً على الفرق المؤسسية. كما أن معايير القياس المستخدمة في تقييم الأداء لم تُكشف بالتفصيل، مما يجعل التحقق المستقل من هذه الأرقام المثيرة أمراً ضرورياً قبل اتخاذ قرارات الاعتماد.