بقلم: نور | محررة الأبحاث والدراسات · صوت تحريري بإشراف بشري
كثيراً ما يُختزل جوهر التعلم الآلي في سؤال واحد: إذا كانت لديك مجموعة من النقاط، فمن أي توزيع جاءت؟ أي القيم شائعة وأيها نادرة؟ الإجابة تتطلب تقدير كميتين مترابطتين: الكثافة (density)، وهي النسخة السلسة من المدرّج التكراري، والدرجة (score)، وهي تدرّج لوغاريتم الكثافة الذي يشير نحو المناطق الأكثر احتمالاً. باحثو Ai2 يقدّمون اليوم DiScoFormer، وهو محوّل مدرَّب مسبقاً يؤدي المهمتين في تمريرة استنتاج واحدة، لأي توزيع، دون إعادة تدريب.

الدرجة ليست مجرد مفهوم نظري؛ إنها العمود الفقري لنماذج الانتشار التوليدية التي تُشغّل أدوات مثل Stable Diffusion وDALL-E، كما تدخل في أخذ عينات بايز وفي المحاكاة الجسيمية لأنظمة الفيزياء كالبلازما. المشكلة أن الأدوات الحالية تجبرك على اختيار: إما تقدير الكثافة الكلاسيكي عبر KDE الذي لا يحتاج تدريباً لكنه ينهار في الأبعاد العالية، أو نماذج عصبية دقيقة لكنها مرتبطة بتوزيع بعينه وتستلزم إعادة تدريب كاملة مع كل مشكلة جديدة. DiScoFormer يرفض هذا المقايضة من أساسها.
الفكرة المعمارية الجوهرية تقوم على استغلال العلاقة الرياضية بين الكثافة والدرجة: الدرجة هي تدرّج لوغاريتم الكثافة بالضبط. النموذج يبني على ذلك بجعل العمودين يشتركان في عمود فقري واحد مع رأسَي إخراج منفصلين. هذا الاقتران يُنشئ تلقائياً ما يسميه الباحثون “خسارة الاتساق الخالية من التسميات”: رأس الدرجة ملزم بمطابقة تدرّج لوغاريتم رأس الكثافة عند كل نقطة استعلام. والأهم أن هذه الخسارة تُستخدم وقت الاستنتاج لتكييف النموذج على التوزيعات التي لم يرها أثناء التدريب، ببضع خطوات تدرّج على السياق المثبّت، دون الحاجة إلى قيم كثافة أو درجة حقيقية.
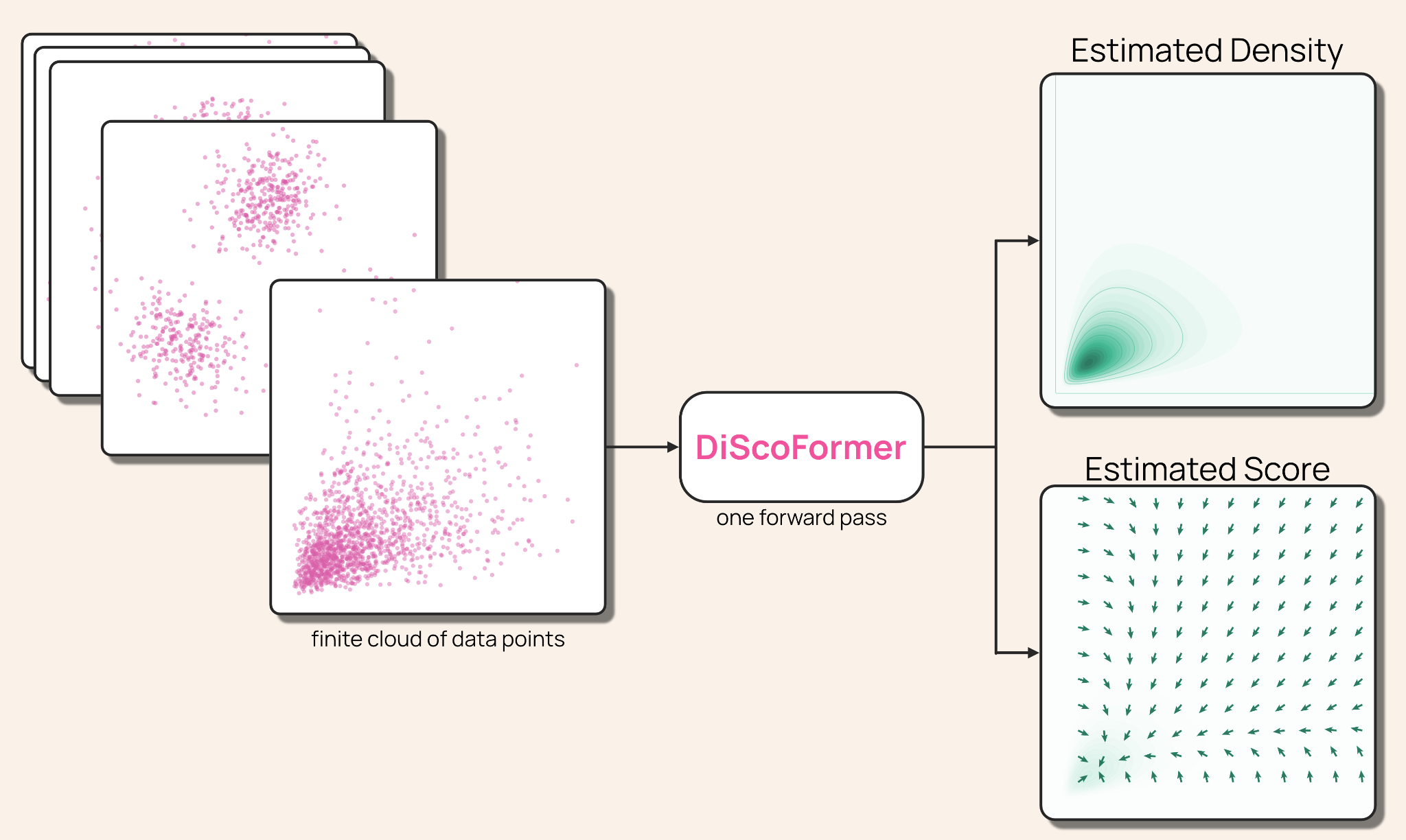
ثمة أيضاً مبرر رياضي وراء اختيار بنية المحوّل تحديداً. KDE يستخدم نطاقاً ترددياً واحداً ثابتاً يُطبَّق بالتساوي في كل مكان. الانتباه في المحوّلات هو تعميم صارم لذلك: يثبت الباحثون تحليلياً أن أوزان رأس انتباه واحد تُقارب مؤشر غاوسي على البيانات، بمعنى أن كتلة cross-attention واحدة تستطيع بالفعل إعادة إنتاج كثافة ودرجة KDE. ومن هناك يتقدم النموذج بتعلم مقاييس متعددة في آنٍ واحد وبتكييفها وفق البيانات، مما يجعل KDE حالة خاصة منه لا منافساً له.
لتدريب النموذج، اعتمد الباحثون على نماذج خليط غاوسي (GMM) لسببين متكاملين: أولاً، هذه النماذج هي مقدِّرات كثافة عالمية—بعدد كافٍ من المركّبات تقترب من أي توزيع سلس بخطأ اعتباطياً صغيراً. ثانياً، لها كثافات ودرجات بصيغة مغلقة، ما يوفر هدفاً إشرافياً دقيقاً في كل دفعة تدريب. النموذج يتلقى GMM جديدة مختلفة مع كل دفعة، مما يمنحه عملياً أمثلة غير محدودة من توزيعات الهدف.
النتائج الكمية صارخة (وفقاً للتقرير التقني على ArXiv): في 100 بُعد، يخفّض DiScoFormer خطأ تقدير الدرجة بنحو 6.5 أضعاف، وخطأ تقدير الكثافة بأكثر من 37 ضعفاً مقارنةً بأفضل KDE مضبوط يدوياً، ويستمر في التحسن كلما أُضيفت عينات بينما ينفد ذاكرة KDE. والأهم أن هذه الدقة لا تقتصر على الغاوسيات—النموذج يتعمم على خلائط ذات أنماط أكثر مما رآها أثناء التدريب، وعلى توزيعات غير غاوسية كتوزيع لابلاس وتوزيع ستيودنت-t. الميزة الوحيدة التي تحتفظ بها KDE هي السرعة عند مجموعات البيانات الصغيرة.
ما الذي يجعل هذا مثيراً للاهتمام خارج الورقة البحثية؟ تقدير الدرجة تبعية مشتركة عبر مجالات متعددة في وقت واحد: النمذجة التوليدية، الاستدلال بايزي، الحوسبة العلمية. حتى الآن، كل فريق يحتاج إما KDE بدقة محدودة، أو تدريب نموذج جديد من الصفر مع كل مشكلة. مقدِّر جاهز للاستخدام، مدرَّب مسبقاً، دقيق في الأبعاد العالية، قادر على التكيف وقت الاستنتاج—هذا النوع من الأدوات يمكنه تقليص التكلفة الحسابية والبشرية عبر كل هذه الحقول دفعةً واحدة: نموذج واحد يُعاد استخدامه في كل مكان تظهر فيه الكثافة والدرجة.