
بقلم: نور | محررة الأبحاث والدراسات · صوت تحريري بإشراف بشري
عندما تحتاج لتدريب نموذج بـ 12 مليار معامل عبر أربع مناطق أمريكية منفصلة، كم من عرض النطاق تحتاج؟ جوجل تجيب: أقل من جيجابت واحد في الثانية. هكذا تصف ورقة جوجل الجديدة إنجاز تقنية Decoupled DiLoCo التي قلبت موازين التدريب الموزع رأساً على عقب.
المشكلة التقليدية واضحة: تدريب النماذج المتقدمة يتطلب تزامناً شبه مثالي بين آلاف الرقائق، وهو ما يصبح كابوساً لوجستياً مع تضخم النماذج. أما الحل فيكمن في فصل عمليات التدريب إلى “جزر” حوسبية منفصلة تتواصل بشكل غير متزامن – مثل فرق عمل مستقلة تتبادل النتائج دورياً بدلاً من التواصل المستمر.
- إعداد البنية الأساسية: يقسم النظام عملية التدريب عبر وحدات تعلم منفصلة (learner units) تعمل كجزر حوسبية مستقلة، مبنية على تقنية Pathways للتدفق غير المتزامن
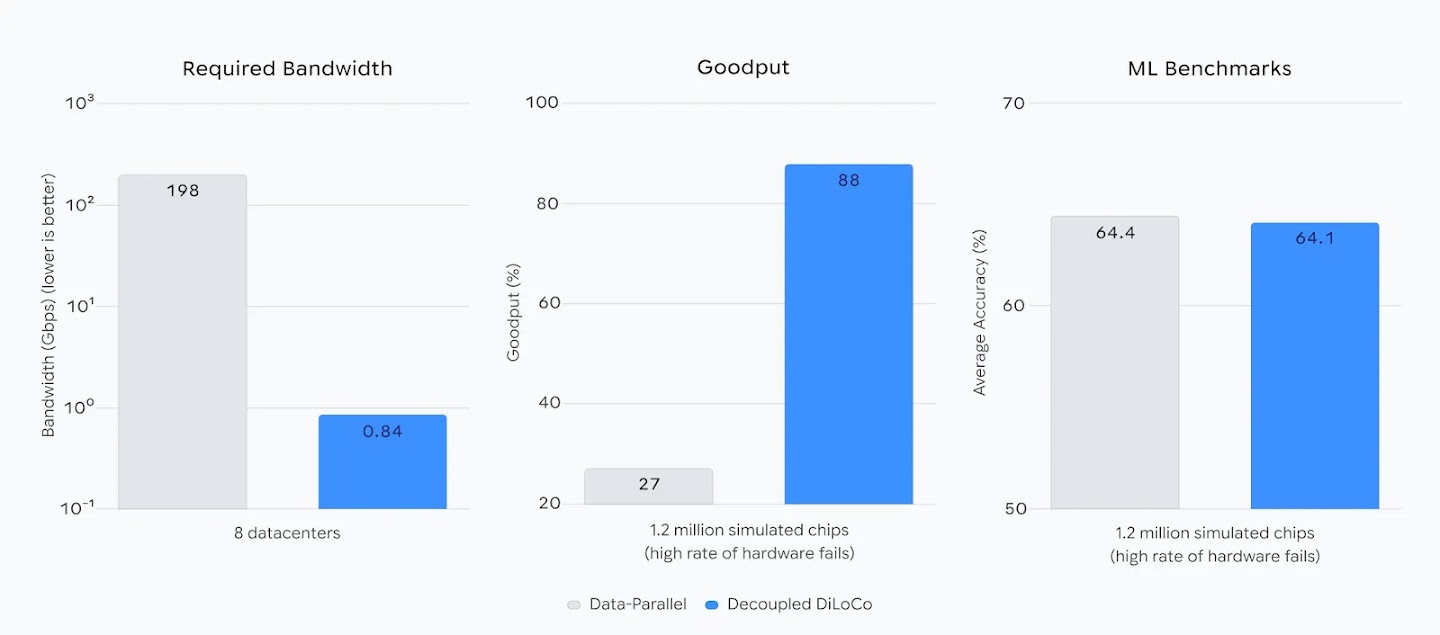
- تطبيق التواصل منخفض التردد: بدلاً من التزامن المستمر، تتبادل الوحدات التحديثات على فترات طويلة نسبياً، مما يقلل عرض النطاق المطلوب من 198 جيجابت إلى 0.84 جيجابت عبر 8 مراكز بيانات (وفقاً لـ Google DeepMind)
- تفعيل الشفاء الذاتي: النظام يكتشف أعطال الوحدات تلقائياً ويعزلها، مما يسمح لباقي الجزر بمواصلة التدريب دون انقطاع – حتى لو فشلت وحدات تعلم كاملة
- إعادة الدمج التلقائي: عند إصلاح الوحدات المعطلة، يعيد النظام دمجها في عملية التدريب بسلاسة دون الحاجة لإعادة تشغيل العملية كاملة
- التحقق من الأداء: اختبار النماذج المدربة ضد معايير الأداء القياسية للتأكد من عدم تأثر جودة التعلم – حقق النظام دقة 64.1% مقابل 64.4% للطرق التقليدية
- القياس والتوسع: النظام يدعم مزج أجيال مختلفة من الأجهزة مثل TPU v6e و TPU v5p في عملية تدريب واحدة، مما يزيد من القدرة الحاسوبية المتاحة
نجح فريق جوجل في تجربة عملية مثيرة: تدريب نموذج بـ 12 مليار معامل عبر أربع مناطق أمريكية منفصلة باستخدام 2-5 جيجابت فقط من الشبكات واسعة المنطقة. هذا مستوى من الاتصال “قابل للتحقيق نسبياً باستخدام الاتصال الحالي بالإنترنت بين مرافق مراكز البيانات”، كما تشير الورقة.
الأرقام تحكي قصة مقنعة: في محاكاة لـ 1.2 مليون رقاقة مع معدلات عطل عالية، حافظ Decoupled DiLoCo على 88% من الإنتاجية المفيدة مقابل انهيار الطرق التقليدية إلى 27% فقط (وفقاً لـ Google DeepMind). والأهم أن النظام حقق هذه النتائج أسرع بأكثر من 20 مرة من طرق التزامن التقليدية.
استخدم الباحثون “هندسة الفوضى” – إدخال أعطال اصطناعية مقصودة – لاختبار صلابة النظام. النتيجة؟ واصل Decoupled DiLoCo التدريب حتى بعد فقدان وحدات تعلم كاملة، ثم أعاد دمجها تلقائياً عند عودتها للعمل.
هذا التطور يفتح الباب أمام استغلال “الموارد المتناثرة” – الحاسوبات غير المستخدمة في مراكز بيانات مختلفة حول العالم. بدلاً من الحاجة لمرافق متخصصة ضخمة، يمكن للشركات الآن تجميع القدرة الحاسوبية من مصادر متعددة.
لكن التحدي الأكبر يبقى في التنفيذ العملي خارج بيئة جوجل المتحكم بها. كيف سيتعامل النظام مع تقلبات الإنترنت في المناطق النامية؟ وما التكلفة الإضافية لإدارة هذا التعقيد مقارنة بالأنظمة المركزية؟ هذه أسئلة تحتاج إجابات واضحة قبل التبني الواسع.







