
بقلم: سارة | محررة نماذج الذكاء الاصطناعي
كشفت جوجل ديب مايند النقاب عن Gemma 4، عائلة النماذج المفتوحة الأكثر تطوراً في تاريخها، والتي تحدث نقلة نوعية في الحوسبة المحلية للذكاء الاصطناعي. النماذج الجديدة تتوزع على أربعة أحجام متخصصة تخدم بيئات حاسوبية متنوعة: E2B وE4B للأجهزة المحمولة والإنترنت of Things، و26B Mixture of Experts و31B Dense للحواسيب الشخصية ومحطات العمل.
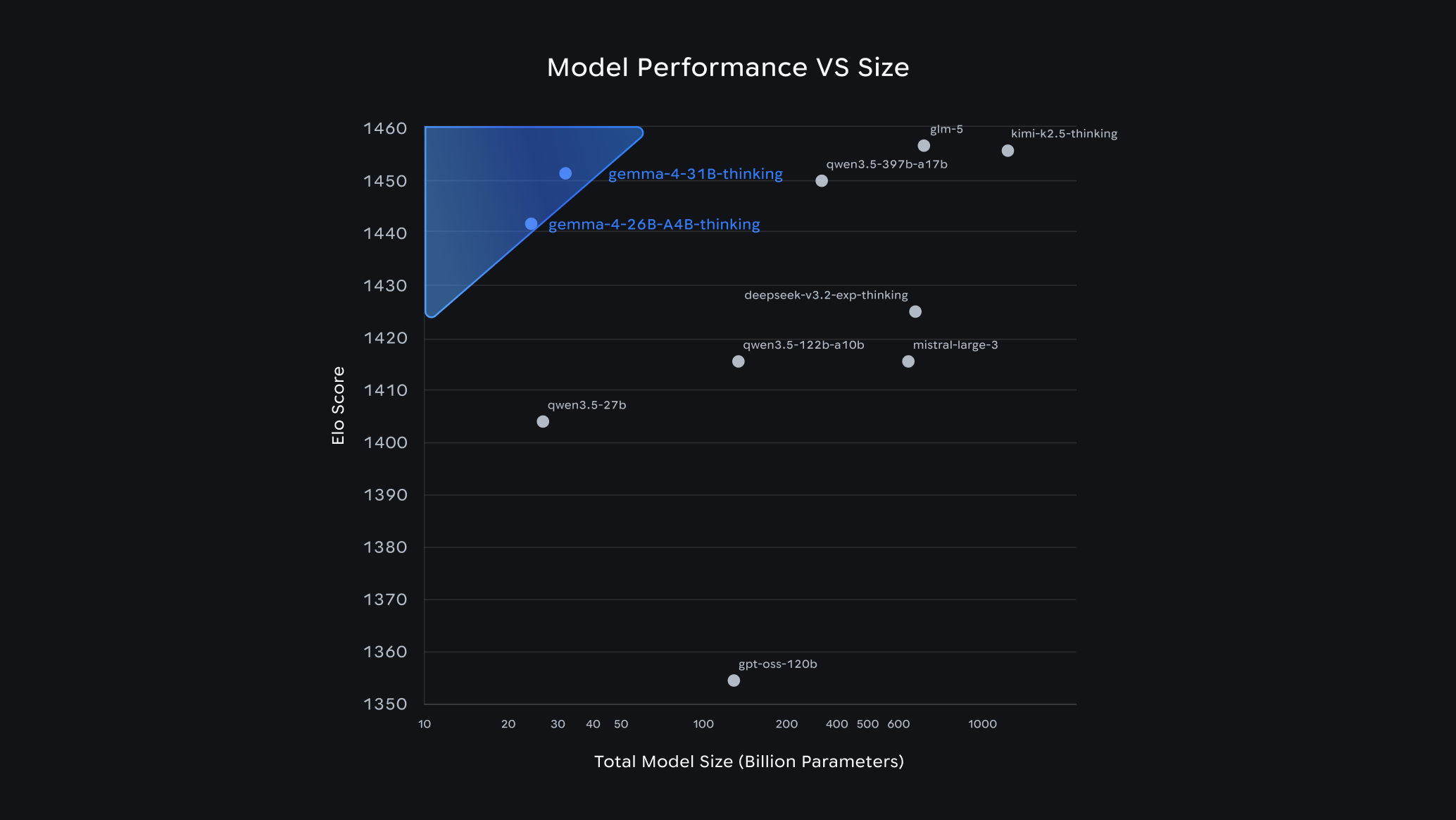
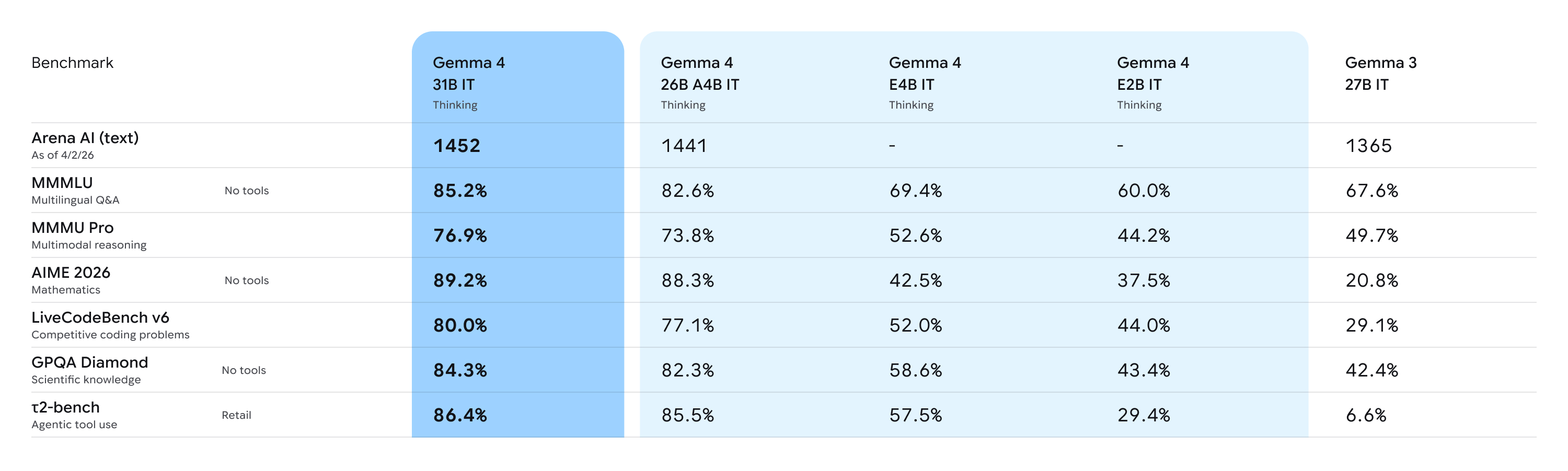
النتائج التنافسية مثيرة للانتباه. نموذج 31B يحتل حالياً المركز الثالث عالمياً في تصنيف Arena AI للنماذج المفتوحة، بينما يحقق نموذج 26B MoE المركز السادس (وفقاً لتصنيف Arena AI). الأهم من ذلك أن هذه النماذج تنافس نماذج أكبر منها بـ20 ضعفاً من حيث عدد البارامترات، مما يعكس تحولاً جذرياً في كفاءة الذكاء لكل بارامتر.
الابتكار التقني يكمن في التصميم المُخصص لكل فئة من النماذج. نماذج 26B و31B مُحسّنة لتعمل أوزانها غير المضغوطة بتنسيق bfloat16 بكفاءة على وحدة GPU واحدة NVIDIA H100 بسعة 80GB. للاستخدام المحلي، النسخ المضغوطة تعمل أصلياً على وحدات GPU الاستهلاكية لتشغيل بيئات التطوير المتكاملة والمساعدين البرمجيين وسير العمل الآلي.
التخصص واضح في النموذجين الكبيرين: 26B MoE يركز على زمن الاستجابة بتفعيل 3.8 مليار بارامتر فقط من إجمالي بارامتراته أثناء الاستنتاج لتحقيق سرعة استثنائية في الرموز المميزة لكل ثانية، بينما 31B Dense يُعظم الجودة الخام ويقدم أساساً قوياً لعمليات الضبط الدقيق المخصصة.
في الطرف الآخر، نماذج E2B وE4B مُهندسة من الأساس لأقصى كفاءة حاسوبية وذاكرة، تفعل بصمة 2 مليار و4 مليار بارامتر فعال أثناء الاستنتاج للحفاظ على ذاكرة الوصول العشوائي وعمر البطارية. جوجل تعاونت بشكل وثيق مع فريق Google Pixel وقادة الأجهزة المحمولة مثل Qualcomm Technologies وMediaTek لضمان تشغيل هذه النماذج متعددة الوسائط بالكامل دون اتصال بالإنترنت مع زمن استجابة يقارب الصفر على الأجهزة الطرفية من الهواتف إلى Raspberry Pi و NVIDIA Jetson Orin Nano.
القدرات الجديدة تشمل طيفاً واسعاً من الميزات المتقدمة. التفكير المنطقي المتقدم يمكن النماذج من التخطيط متعدد الخطوات والمنطق العميق، مع تحسينات كبيرة في مقاييس الرياضيات وتتبع التعليمات. سير العمل الآلي للوكلاء يتضمن دعماً أصلياً لاستدعاء الدوال والإخراج المنظم JSON والتعليمات النظام الأصلية، مما يمكن بناء وكلاء مستقلين يتفاعلون مع أدوات وواجهات برمجة تطبيقات مختلفة وينفذون سير العمل بموثوقية.
إنتاج الكود عالي الجودة دون اتصال بالإنترنت يحول محطة العمل إلى مساعد برمجي محلي متقدم، بينما المعالجة الأصلية للفيديو والصور تدعم دقة متغيرة وتتفوق في مهام التعرف البصري على الحروف وفهم الرسوم البيانية. النماذج E2B وE4B تتضمن إضافياً إدخالاً صوتياً أصلياً للتعرف على الكلام والفهم اللغوي الصوتي.
نوافذ السياق تحقق قفزة كمية: النماذج الطرفية تقدم 128K رمز مميز، بينما تصل النماذج الأكبر إلى 256K رمز مميز (وفقاً لجوجل ديب مايند)، مما يسمح بتمرير مستودعات كود كاملة أو مستندات مطولة في استعلام واحد. التدريب الأصلي على أكثر من 140 لغة يمكن المطورين من بناء تطبيقات شاملة وعالية الأداء لجمهور عالمي.
التحول في الترخيص جاء استجابة مباشرة لملاحظات المجتمع. تُطرح Gemma 4 تحت رخصة Apache 2.0 التجارية المرنة، مقدمة أساساً للمرونة التطويرية الكاملة والسيادة الرقمية. هذا يمنح المطورين سيطرة كاملة على البيانات والبنية التحتية والنماذج، مع إمكانية البناء بحرية والنشر الآمن عبر أي بيئة، سواء محلياً أو سحابياً. النجاح السابق ملحوظ: نماذج Gemma من الجيل الأول حُملت أكثر من 400 مليون مرة وأنتجت أكثر من 100,000 متحور في المجتمع (وفقاً لإحصائيات جوجل).
النظام البيئي التقني جاهز من اليوم الأول. يمكن الوصول الفوري إلى Gemma 4 والبدء في البناء مباشرة عبر Google AI Studio للنماذج الكبيرة أو Google AI Edge Gallery للنماذج الطرفية. مطوروا أندرويد يمكنهم استخدامها لتشغيل Agent Mode في Android Studio والبدء في بناء تطبيقات إنتاجية على أندرويد باستخدام ML Kit GenAI Prompt API.
الدعم الواسع للأدوات يشمل المنصات المفضلة مع دعم اليوم الأول لـ Hugging Face وvLLM وllama.cpp وMLX وOllama وNVIDIA NIM وNeMo، مما يتيح المرونة في اختيار أفضل الأدوات للمشروع. يمكن تنزيل أوزان النماذج من Hugging Face أو Kaggle أو Ollama، مع إمكانية التخصيص والضبط باستخدام المنصة المفضلة مثل Google Colab أو Vertex AI أو حتى وحدات GPU للألعاب.
للتوسع الإنتاجي، بينما الاستنتاج المحلي مثالي للاستخدام دون اتصال، Google Cloud تزيل جميع قيود الحوسبة. النشر متاح عبر Vertex AI وCloud Run وGKE وSovereign Cloud وخدمة TPU المسرعة مع أعلى ضمانات الامتثال للأعباء العمل المنظمة. النماذج مُحسّنة للأجهزة الرائدة في الصناعة خارج الصندوق، مع أقصى أداء على بنية NVIDIA التحتية من NVIDIA Jetson Orin Nano إلى معالجات Blackwell، والتكامل مع وحدات AMD GPU عبر مكدس ROCm مفتوح المصدر، أو النشر على معالجات Trillium وIronwood TPUs للنطاق الضخم والكفاءة.
المنافسة العلمية مستمرة من خلال تحدي Gemma 4 الخيري على Kaggle لبناء منتجات تخلق تغييراً إيجابياً ذا معنى في العالم. لكن التحدي العملي للمطورين يكمن في الاختيار الصحيح بين النماذج حسب حالة الاستخدام وقيود الموارد، خاصة عند الموازنة بين سرعة MoE وجودة Dense للتطبيقات المحددة.







