بقلم: يوسف | محرر أدوات الذكاء الاصطناعي · صوت تحريري بإشراف بشري
كشفت Liquid AI عن LFM2.5-8B-A1B، نموذج Mixture-of-Experts محسّن للعمل على الأجهزة المحلية بقدرات متقدمة في استدعاء الأدوات. النموذج الجديد يبني على LFM2-8B-A1B المطلق في أكتوبر 2025 مع توسيعات جذرية في التدريب والقدرات.
التطويرات الرئيسية تشمل توسيع نافذة السياق من 32,768 إلى 128,000 رمز، وتوسيع التدريب المسبق من 12 إلى 38 تريليون رمز، وإضافة تعلم تعزيزي واسع النطاق. الشركة ضاعفت أيضاً حجم المفردات إلى 128,000 لتحسين كفاءة الترميز للغات غير اللاتينية (وفقاً لـ Liquid AI).
النتيجة نموذج قادر على ربط استدعاءات الأدوات وإنجاز المهام المعقدة حتى على أجهزة لاب توب المبتدئين. النموذجان الأساسي (LFM2.5-8B-A1B-Base) والمدرب لاحقاً (LFM2.5-8B-A1B) متاحان الآن على Hugging Face ومنصة Playground.
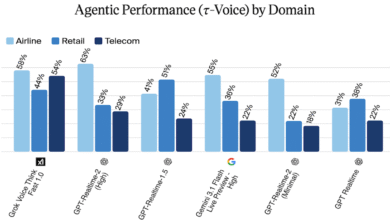
الأداء المضغوط يتنافس مع نماذج كثيفة وMoE أكبر بكثير في مهام اتباع التعليمات والوكلاء الذكيين. على مؤشر AA-Omniscience Index، قفز النموذج من -78.42 إلى -24.70، بينما ارتفع معدل عدم الهلوسة بشكل هائل من 7.46% إلى 63.47% (وفقاً لـ Liquid AI).
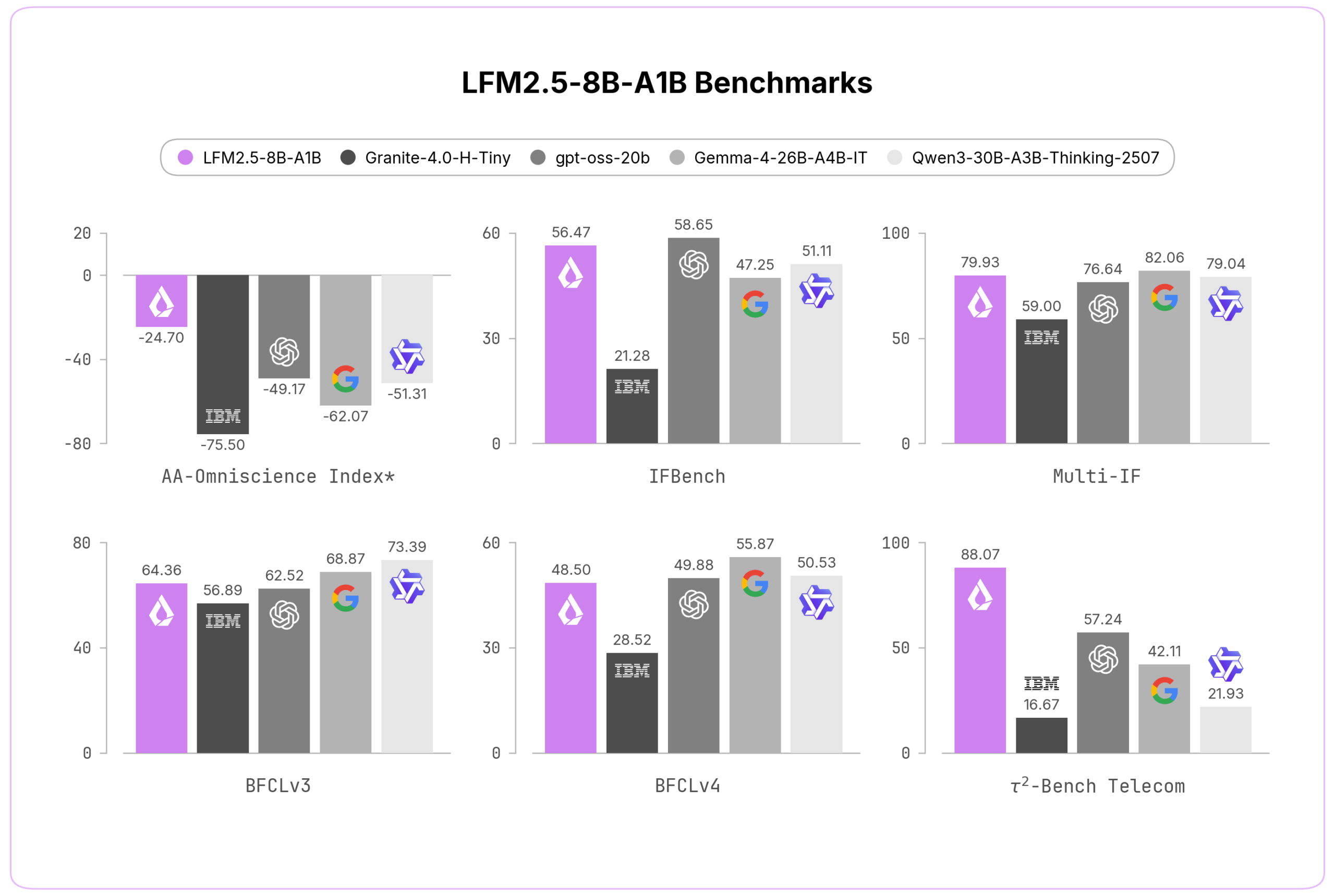
التحسينات في الترميز مثيرة خاصة للمطورين العرب. المعجم الجديد حقق كفاءة +38.8% للعربية، +120.4% للهندية، +238.2% للتايلاندية، و+117.9% للفيتنامية مقارنة بالمعجم السابق (وفقاً لـ Liquid AI). هذا يعني معالجة أسرع ونتائج أدق للنصوص العربية.
الأداء الحاسوبي لا يقل إثارة. على معالج M5 Max، يحقق النموذج 253 رمز/ثانية في القراءة والتوليد مع استهلاك أقل من 6 جيجابايت ذاكرة. على Ryzen AI Max+ 395 يصل إلى 146 رمز/ثانية. حتى على الهاتف المحمول، يحافظ على ~30 رمز/ثانية (وفقاً لـ Liquid AI).
في بيئات GPU الإنتاجية، يحقق النموذج 18,500 رمز إخراج/ثانية على NVIDIA H100 واحدة في مستويات التزامن العالية، أي أكثر من 1.6 مليار رمز يومياً على معالج واحد.
التطبيق العملي الأبرز هو LocalCowork، المساعد المكتبي مفتوح المصدر الذي يعمل الآن على LFM2.5-8B-A1B. النظام يدير 67 أداة عبر 13 خادم MCP على لاب توب واحد دون سحابة أو مفاتيح API، مع بيانات لا تغادر الجهاز أبداً. حلقة إرسال الأدوات تشعر تفاعلية على العتاد الاستهلاكي بأقل من ثانية لكل عملية إرسال.
النموذج يدعم فورياً منصات الاستنتاج الرئيسية: llama.cpp للحافة، MLX لـ Apple Silicon، vLLM وSGLang للإنتاج المسرع، وONNX للاستنتاج متعدد المنصات. هذا الدعم الواسع يجعل النشر سهلاً عبر عتاد متنوع من Apple وAMD وIntel وQualcomm وNvidia.
الحدود الواضحة تكمن في سعة المعرفة المحدودة للنماذج الحافية، مما يؤدي لهلاوس أكثر مقارنة بالنماذج الضخمة. Liquid AI تعاملت مع هذا عبر مرحلة تعلم تعزيزي مستهدفة لتعزيز الامتناع عن الإجابة في الاستفسارات خارج المعرفة الموثوقة.