بقلم: يوسف | محرر أدوات الذكاء الاصطناعي · صوت تحريري بإشراف بشري
تدخل إنڤيديا معركة الذكاء الاصطناعي متعدد الوسائط بسلاح جديد قد يغير قواعد اللعبة. النموذج الجديد Nemotron 3 Nano Omni لا يكتفي بقراءة النصوص أو مشاهدة الصور، بل يجمع بين فهم المستندات المعقدة والملفات الصوتية ومقاطع الفيديو في نظام واحد مصمم للتعامل مع أكثر المهام تحدياً في الواقع العملي.
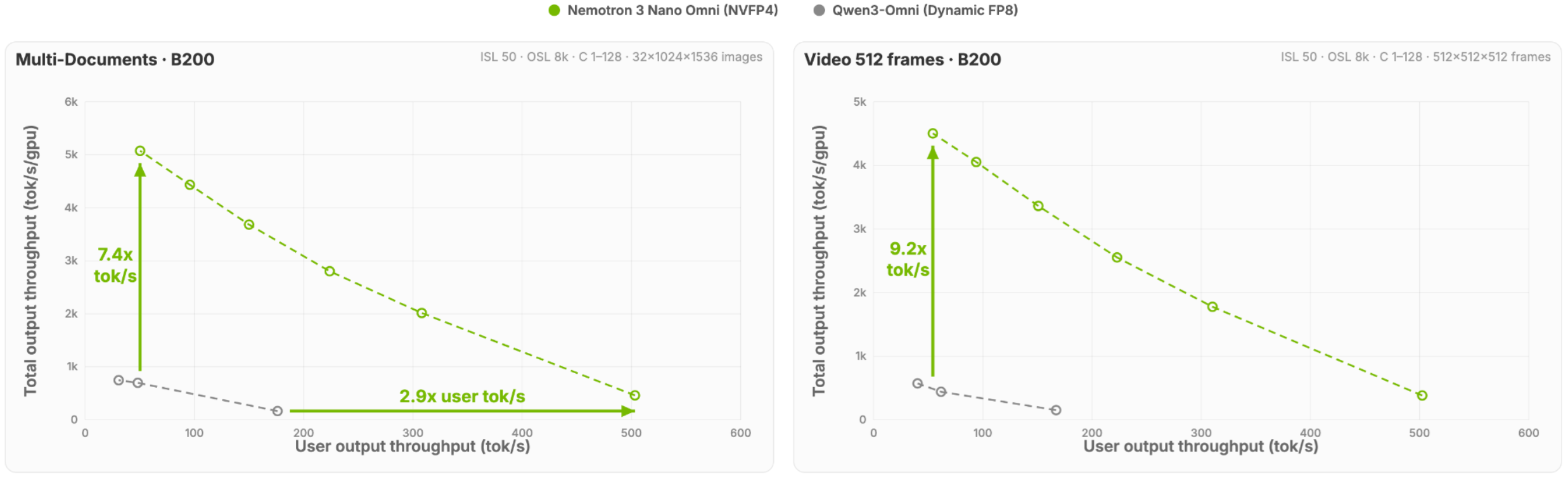
النتائج على المعايير المرجعية تكشف تفوقاً واضحاً: 65.8 نقطة على OCRBenchV2 مقابل 61.2 للإصدار السابق، و57.5 نقطة على MMLongBench-Doc مقابل 38.0 سابقاً. على صعيد الفيديو والصوت، يحقق 72.2 نقطة على Video-MME و89.4 على VoiceBench (وفقاً لإنڤيديا). لكن الإنجاز الحقيقي يكمن في الكفاءة التشغيلية: النموذج يحقق 7.4 ضعف الكفاءة في حالات المستندات المتعددة و9.2 ضعف في معالجة الفيديو مقارنة بالمنافسين.
- تحليل المستندات الواقعية المعقدة: يتجاوز النموذج حدود التعرف الضوئي التقليدي ليفهم التخطيطات المعقدة والجداول والرسوم البيانية والمعادلات عبر المستندات الطويلة. يمكنه التعامل مع عقود من 100+ صفحة، والأوراق التقنية المتخصصة، وتقارير الامتثال، والنماذج متعددة الصفحات مع الحفاظ على فهم المراجع المتقاطعة بين الصفحات
- التعرف التلقائي المتقدم على الكلام: قدرات نسخ عالية الدقة تتعامل مع الصوت طويل المدى حتى 20 دقيقة، مع دعم متحدثين متعددين ولهجات مختلفة وضوضاء خلفية متنوعة. النموذج يدمج هذه القدرات في سير العمل الأوسع لتحليل المحتوى المنطوق وربطه بالوسائط الأخرى
- فهم الصوت والفيديو المدمج: يتخصص في السيناريوهات المختلطة مثل تسجيلات الشاشة المصحوبة بتعليق صوتي، وفيديوهات التدريب التفاعلية، والاجتماعات مع العروض التقديمية، والدروس التطبيقية، وعروض المنتجات، وتسجيلات الدعم الفني، وأرشيف الفيديو طويل المدى
- التحكم الوكيل في الحاسوب: تدريب متخصص للمساعدة في بيئات الواجهة الرسومية من خلال تفسير لقطات الشاشة ومراقبة حالة واجهة المستخدم وربط الاستدلال بالعناصر المرئية على الشاشة ومساعدة اختيار الإجراءات أو أتمتة سير العمل
- الاستدلال العام متعدد الوسائط: يتجاوز الإدراك البسيط ليتفوق في المهام كثيفة الاستدلال التي تتطلب تجميع المعلومات عبر نوافذ سياق طويلة ووسائط متعددة وأدلة منظمة أو شبه منظمة، مع قدرة على الاستدلال متعدد الخطوات وإجراء العمليات الحسابية
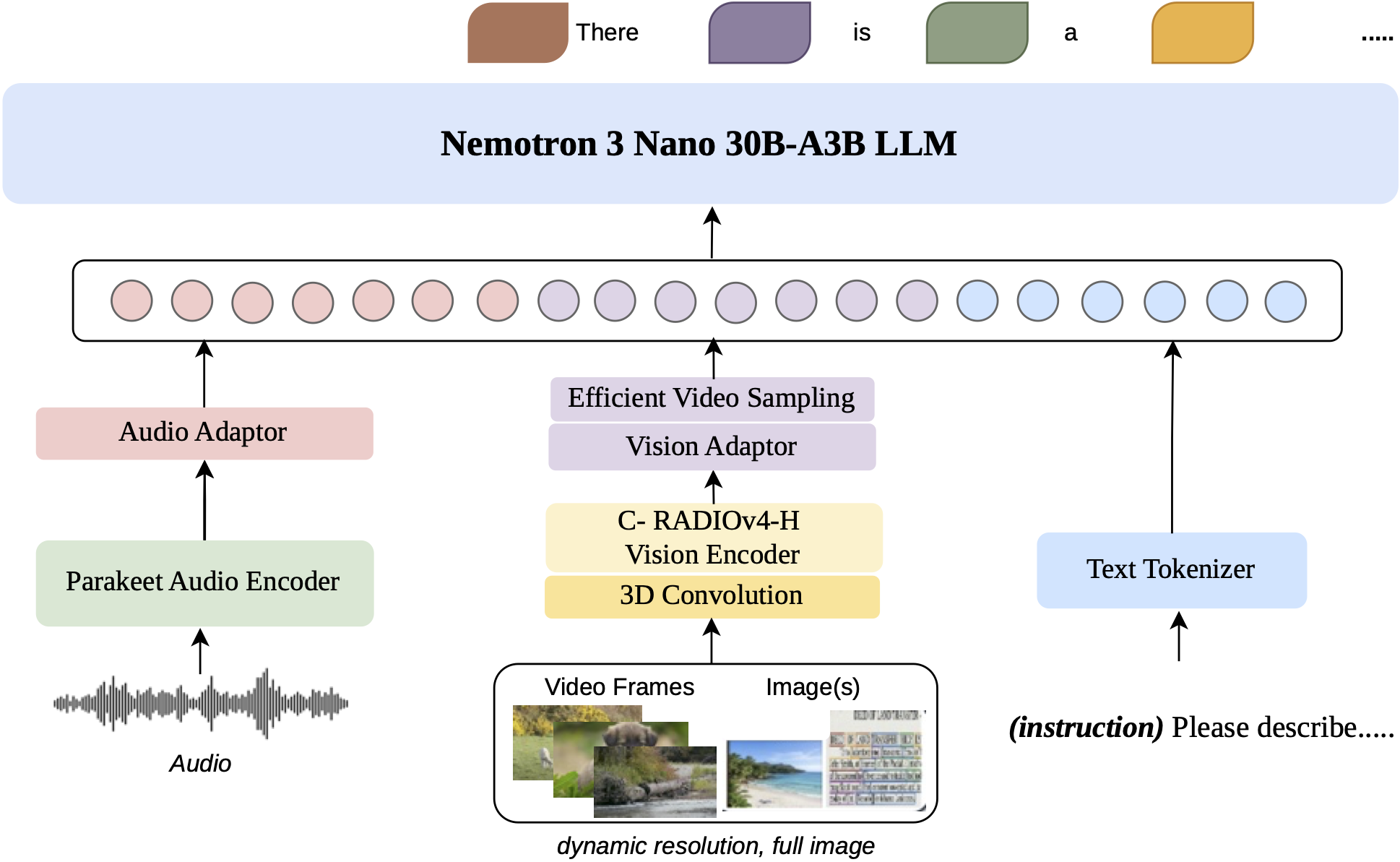
التطور التقني الحقيقي يكمن في المعمارية الهجينة التي تجمع 23 طبقة Mamba للمعالجة الفعالة للسياق الطويل، و23 طبقة خبراء مختلطة مع 128 خبيراً وتوجيه للأفضل-6، و6 طبقات انتباه مجمعة الاستعلام. على صعيد الرؤية، النموذج يستبدل استراتيجية التقسيم المستخدمة في الإصدار الثاني بمعالجة دقة ديناميكية بنسبة العرض إلى الارتفاع الأصلية، مما يسمح بتمثيل كل صورة باستخدام عدد متغير من الرقع 16×16، من حد أدنى 1024 إلى حد أقصى 13312 رقعة بصرية لكل صورة.
للفيديو، يستخدم النموذج مساراً مخصصاً لتضمين “التيوبلت” ثلاثي الأبعاد، حيث يدمج كل زوج من الإطارات المتتالية في “تيوبلت” واحد قبل المرور عبر ViT، مما يقلل عدد رموز الرؤية التي يجب على نموذج اللغة الانتباه إليها إلى النصف. تقنية EVS (العينات الفيديو الفعالة) تحذف الرموز المتكررة بعد مرمز الرؤية أثناء الاستنتاج، مما يقلل الكمون ويحسن الإنتاجية مع الحفاظ على الدقة.
على الصعيد الصوتي، النموذج مدعوم بـ Parakeet-TDT-0.6B-v2 المتصل بالعمود الفقري عبر إسقاط MLP ثنائي الطبقة. يتعامل مع الصوت المعينن على 16 كيلوهرتز ويُدرب على مدخلات تصل إلى 1200 ثانية (20 دقيقة)، بينما يدعم الحد الأقصى لسياق نموذج اللغة أكثر من 5 ساعات.
البيانات التدريبية شهدت تطويراً كبيراً بتوليد تقريباً 11.4 مليون زوج سؤال وجواب صناعي (حوالي 45 مليار رمز) من مجموعة كبيرة من ملفات PDF الواقعية باستخدام NeMo Data Designer. هذه المجموعة حققت تحسناً بنسبة 2.19 مرة في الدقة الإجمالية على MMLongBench-Doc (وفقاً لإنڤيديا). التدريب التعزيزي متعدد البيئات يغطي مهاماً من الوضع الأحادي إلى السيناريوهات متعددة الوسائط بالكامل، مع مجموعة متنوعة من المقيمين تقيم المخرجات عبر صيغ مثل الاختيار من متعدد والرياضيات وتأريض الواجهة الرسومية والتعرف على الكلام.
النموذج متاح للتحميل بصيغ BF16 وFP8 وNVFP4 على منصة Hugging Face، مع إتاحة أجزاء كبيرة من كود التدريب كمصدر مفتوح. التدريب تم باستخدام NVIDIA H100 مع توسع من 32 إلى 128 عقدة حسب المرحلة، باستخدام مجموعة Megatron-LM وTransformer Engine وMegatron Energon.
السؤال الذي يطرح نفسه: هل ستكون الكفاءة التشغيلية العالية والقدرات المتقدمة كافية لإقناع المطورين بالانتقال من الحلول الحالية؟ الأرقام مقنعة، لكن التطبيق الواقعي سيحدد مصير هذا النموذج الطموح.