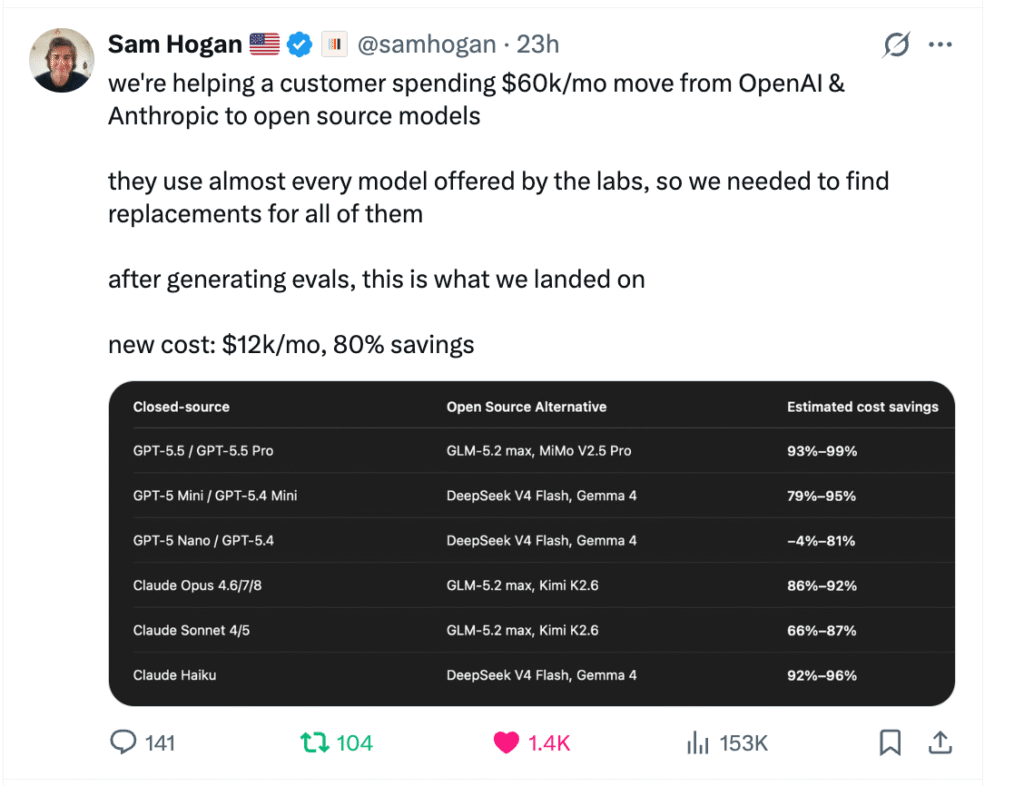
نسيت البحوث الجينية لعقود طويلة 98% من الحمض النووي البشري، واكتفت بدراسة الـ 2% فقط المسؤول عن تكوين البروتينات. اليوم، يغير نموذج AlphaGenome هذا المسار بالكامل عبر تحليل المساحة الشاسعة المُهملة من جينومنا – تلك المنطقة التي تنظم التعبير الجيني وتتحكم في وظائف خلوية حيوية، والتي يطلق عليها العلماء “الحمض النووي المظلم”.
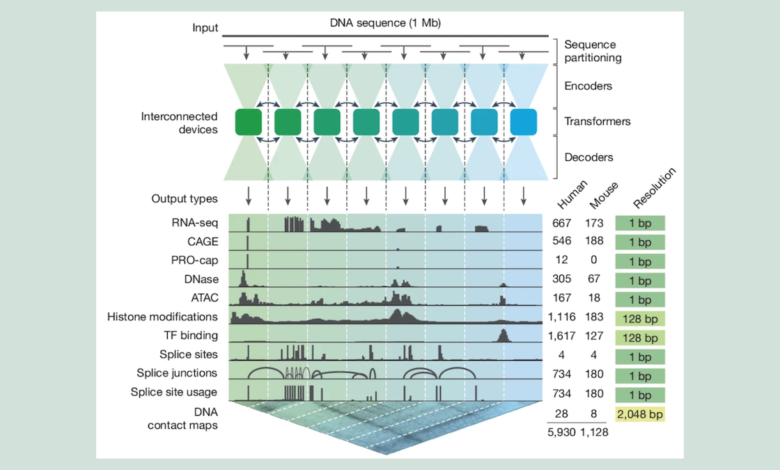
يعالج النموذج مليون زوج من قواعد الحمض النووي كمدخل ليُخرج تحليلاً شاملاً لـ 6000 خاصية جينية للبشر و1000 للفئران. البنية التقنية تجمع بين encoder من النوع CNN لاستخراج الخصائص المحلية، وtransformer لفهم العلاقات بعيدة المدى، وCNN decoder لتحويل المعلومات إلى نتائج قابلة للتفسير.
القفزة الحقيقية تكمن في دقة التحليل. اختبر الباحثون AlphaGenome في 50 تقييماً مختلفاً، فتفوق على النماذج السابقة أو ضاهاها في 47 منها. النموذج قادر على تحديد نقاط بداية ونهاية الجينات بدقة، وحساب كمية RNA التي توجه الخلية لإنتاجها، بل ويرصد المناطق التي تتجاهلها الخلية أثناء قراءة الجين – العملية التي تسبب أمراضاً متنوعة عند حدوث أخطاء فيها.
السر وراء هذا الأداء المتميز يعود لتقنية التقطير المبتكرة. درب الفريق 64 نموذجاً متطابق البنية على تسلسلات جينية من أربع قواعد بيانات عامة ضخمة للبشر والفئران، ثم دمج معرفة جميع النماذج في نموذج واحد. هكذا تعلم AlphaGenome الأداء التجميعي لـ 64 خبيراً مختلفاً في تحليل الجينات.
لكن التحديات العملية واضحة. معالجة مليون زوج قاعدي تتطلب موارد حاسوبية ضخمة، والتدريب اقتصر على بيانات الفئران والبشر فقط. كما أن النموذج متاح للاستخدامات غير التجارية حصراً، رغم توفر API والأوزان وكود الاستدلال مجاناً.
بالنسبة للمطورين في المملكة والإمارات العاملين بمجال التقنية الحيوية، يفتح AlphaGenome فرصاً هائلة لتحليل الخصائص الجينية للسكان العرب. الأمر يتطلب شراكات قوية مع الجامعات والمراكز الطبية، خاصة أن فهم “الحمض النووي المظلم” قد يكشف عن استعدادات وراثية خاصة بمنطقتنا لم تُدرس من قبل.
هذا التطور يضعنا أمام سؤال محوري: هل سنكتفي بتطبيق تقنيات طُورت على بيانات غربية، أم سنستثمر في جمع بيانات جينية عربية لتدريب نماذج مخصصة لخصائصنا الوراثية الفريدة؟