
بقلم: نور | محررة الأبحاث والدراسات · صوت تحريري بإشراف بشري
وكيل واحد يحقق معدل نجاح 87% بينما آخر يحقق 42% رغم استخدامهما لنفس النموذج اللغوي، فما الذي يصنع هذا الفارق الضخم؟
أطلق فريق بحث IBM Open Agent Leaderboard، أول مقياس مفتوح المصدر لتقييم وكلاء الذكاء الاصطناعي العامة بشكل شامل. لا يقيس المقياس النماذج اللغوية فقط، بل الأنظمة الكاملة: الأدوات المتاحة، آليات التخطيط، الذاكرة بين الإجراءات، والتعافي من الأخطاء.
تكمن أهمية هذا المقياس في قياس “العمومية الحقيقية” للوكلاء – قدرتها على أداء مهام متنوعة دون تخصيص يدوي لكل مهمة. يختبر الوكلاء عبر ستة معايير متنوعة: إصلاح أخطاء البرمجة الفعلية في SWE-Bench Verified، البحث المعقد عبر الإنترنت في BrowseComp+، المهام الشخصية عبر مئات التطبيقات في AppWorld، وخدمة العملاء والدعم التقني عبر tau2-Bench Airline وRetail وTelecom.
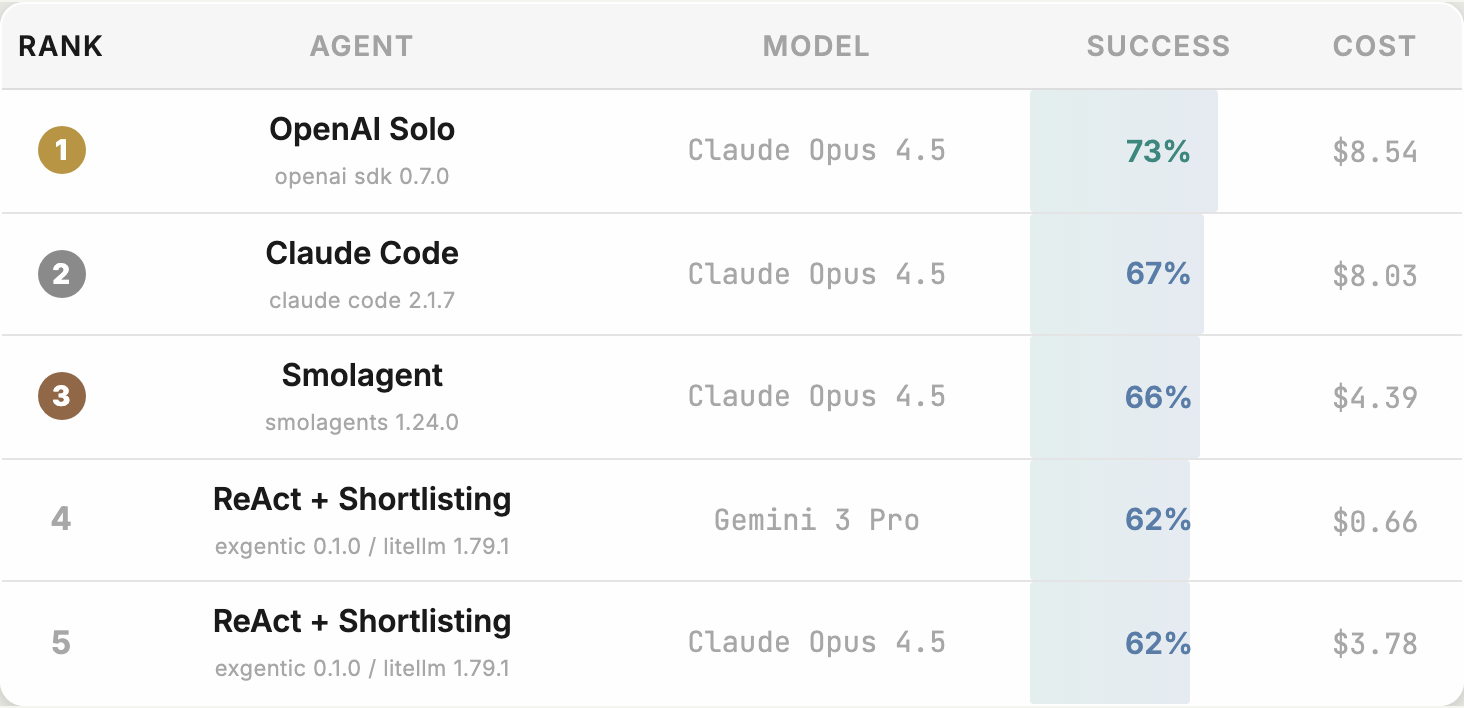
النتائج الحالية تكشف فجوة مذهلة في الأداء. الوكلاء الثلاثة الأولى تستخدم جميعها نفس النموذج اللغوي، لكن معدلات نجاحها تتراوح بين 56% و87% (وفقاً لـ Open Agent Leaderboard). الفجوة في التكلفة أكثر إثارة – الوكيل الأكثر كفاءة يعمل بجزء صغير من تكلفة الأقوى أداءً.
- وكلاء الأغراض العامة تنافس المتخصصة: في عدة حالات، وكلاء لم تخضع لأي تحسين خاص بالمعايير ضاهت أو تفوقت على أنظمة مبنية خصيصاً لتلك المهام.
- أنماط الفشل تختلف جذرياً: بعض الوكلاء تفشل سريعاً وبتكلفة منخفضة، بينما أخرى تحرق الموارد في محاولات طويلة قبل الاستسلام. التشغيلات الفاشلة تكلف 20-54% أكثر من الناجحة.
- اختيار الأدوات المناسب يصنع الفارق: تقنية “tool shortlisting” التي تساعد الوكيل على التركيز على الأدوات ذات الصلة حسّنت الأداء عبر كل النماذج المختبرة، وحوّلت تكوينات فاشلة إلى قابلة للاستخدام.
- النماذج مفتوحة الوزن تتخلف بفجوة كبيرة: أحدث النماذج مفتوحة الوزن DeepSeek V3.2 وKimi K2.5 تتخلف عن النماذج المغلقة بـ18-29 نقطة مئوية في المتوسط.
- معمارية الوكيل بدأت تؤثر: رغم أن اختيار النموذج يظل العامل المهيمن، معمارية الوكيل المحيطة به بدأت تغيّر النتائج بشكل ملحوظ.
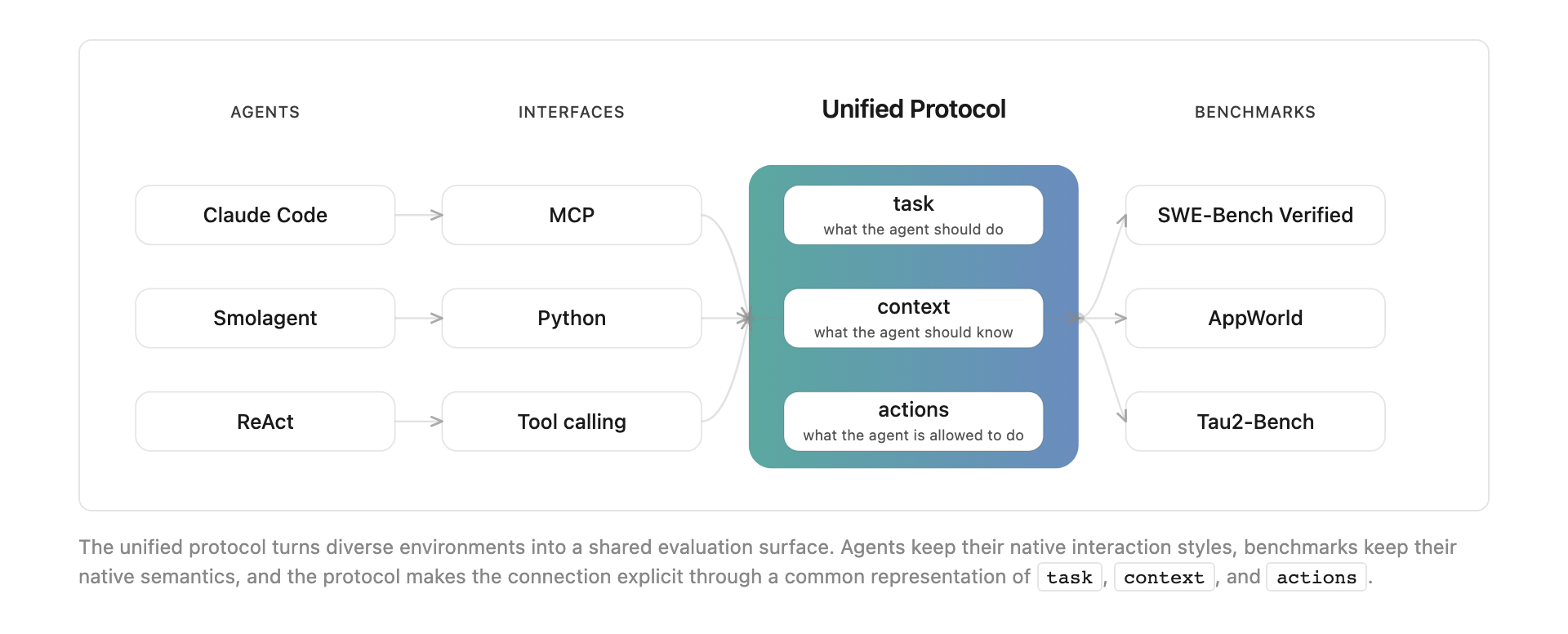
يتميز المقياس بإدخال بروتوكول موحد يعطي كل معيار نفس الشكل: مهمة (ما المطلوب)، سياق (ما المعلوم)، ومجموعة إجراءات (ما المسموح). هذا التوحيد ليس تافهاً – كل معيار يأتي بافتراضاته وتعليماته وأنماط تفاعله الخاصة، والتأكد من عدم تصادمها مع طريقة عمل الوكلاء المختلفة يتطلب فهماً عميقاً للطرفين.
المبادرة مفتوحة المصدر بالكامل عبر منصة Exgentic التي تنسق جلسات التقييم عبر البيئات المتنوعة وتنتج تقارير موحدة للنتائج والمسارات والتكاليف. يمكن لمطوري الوكلاء المساهمة عبر توثيق مكونات أنظمتهم، وصانعي المعايير يمكنهم إضافة مهام جديدة، وأي شخص يمكنه إعادة إنتاج النتائج والتحدي معها.
التحدي الأساسي يكمن في أن معظم المعايير لم تُصمم أصلاً مع وكلاء الأغراض العامة في الاعتبار وتتطلب تكييفاً دقيقاً. لكن النتائج الأولية واعدة، والفريق يسعى لمساهمات في ثلاثة محاور: وكلاء جديدة، معايير جديدة، ونماذج جديدة خاصة مفتوحة الوزن.
الهدف النهائي هو جعل تقييم الوكلاء العامة يعكس ما يُقاس فعلياً: النظام الكامل وليس النموذج فقط. هذا مهم لأن الوكلاء العامة تعيد تشكيل طريقة أداء العمل، والمجتمع يحتاج معايير مشتركة لتقييم ومقارنة وتحسين هذه الأنظمة المفتوحة بشفافية.







