
بقلم: سارة | محررة نماذج الذكاء الاصطناعي · صوت تحريري بإشراف بشري
النماذج اللغوية الكبيرة التي تعمل على هاتفك مباشرة تواجه عقبة بنيوية: كل رمز نصي يستدعي دورة معالجة كاملة، مما يُبطّئ الاستجابة ويُنهك البطارية. غوغل تقول إنها وجدت طريقة لكسر هذا القيد على أجهزة Gemini Nano دون إعادة تدريب النموذج الأصلي من الصفر.
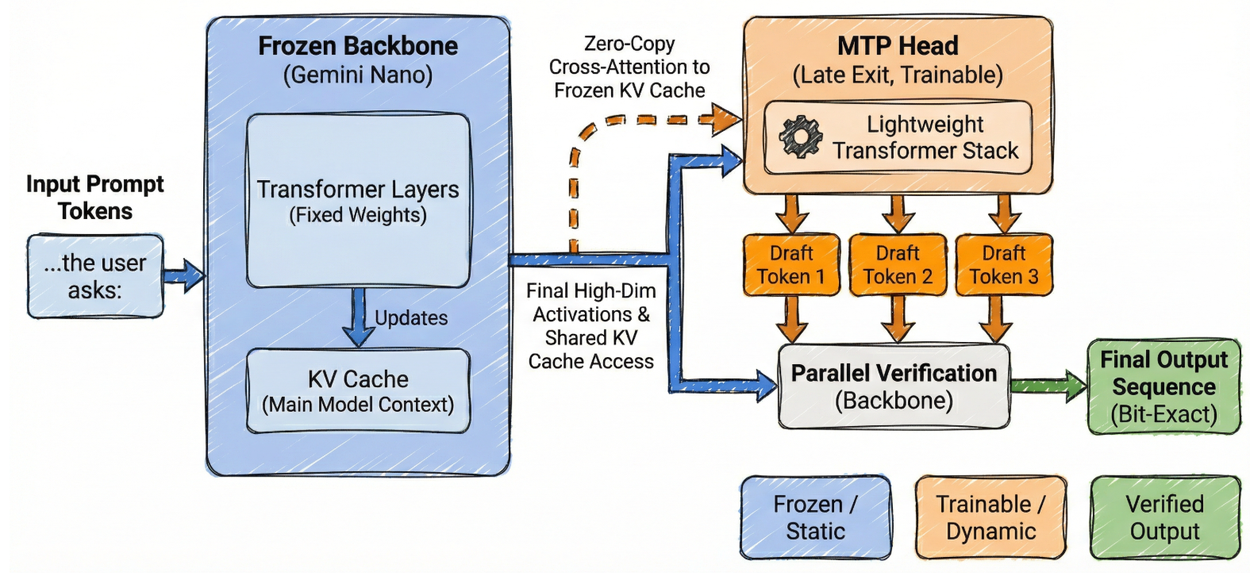
النهج يقوم على تقنية Multi-Token Prediction (MTP) التي تُلصق رأساً خفيفاً من Transformer بالطبقات الأخيرة للنموذج المُجمَّد، فيتنبأ هذا الرأس بعدة رموز دفعة واحدة بدلاً من رمز واحد في كل مرة. الفكرة ليست جديدة كلياً — فإطار EAGLE وCALM طرحا مفاهيم مشابهة — لكن التطبيق الذي أعلنه فريق Google Platforms & Devices يحل مشكلة عملية خاصة بالبيئات الطرفية ذات الذاكرة المحدودة.
الحلقة الأضعف في الأنظمة التقليدية تتمثل في “مُسوِّد” منفصل: نموذج صغير مستقل يقترح الرموز المرشحة، ثم يتحقق منها النموذج الكبير. لكن هذا التصميم يُفرز مشكلتين على الهاتف: أولاً، يحجز المُسوِّد الصغير — بمعاملاته الـ128 مليون — قدراً من ذاكرة RAM في بيئة شحيحة. ثانياً، هذا المُسوِّد أعمى تماماً عن الحالة الداخلية للنموذج الرئيسي، ويتنبأ انطلاقاً من سياق النص وحده دون الإفادة من التمثيلات الغنية التي بناها النموذج الكبير بالفعل.
 Gemini Nano”>
Gemini Nano”>المقاربة الجديدة تُعيد رسم البنية كلياً. بدلاً من نموذج مُسوِّد منفصل، يُضاف رأس Transformer خفيف — يُدرَّب وحده فيما تبقى أوزان النموذج الأصلي مُجمَّدة — إلى الطبقات الأخيرة من Gemini Nano v3. هذا الرأس يسحب التفعيلات النهائية عالية الأبعاد من النموذج الكبير ويستخدمها لتوليد مسلسل من الرموز المرشحة. النموذج الكبير يتحقق منها لاحقاً بالتوازي، فإن طابقت ما كان سيُنتجه أُقرَّت، وإن خالفته أُهملت والنتيجة النهائية تبقى مطابقة بِت-لبِت لما كان سيُنتجه النموذج دون أي تعديل.
التحدي الأدق كان في الذاكرة الديناميكية لا الساكنة. حتى لو شارك المُسوِّد أوزاناً ثابتة مع النموذج الرئيسي، فإنه إن عالج السياق بصورة مستقلة يُراكم KV Cache خاصاً به — ضريبة مضاعفة على الذاكرة في هاتف يعمل بموارد محدودة. الحل الذي طوّره الفريق هو ما يُسمونه zero-copy architecture: رأس MTP لا يبني كاش خاصاً، بل يتقاطع مباشرةً مع KV Cache للنموذج الأصلي عبر آلية cross-attention. هذا يعني أن الرأس لا يُعيد معالجة المدخلات ولا يُهدر وقتاً في prefill، ويُوفّر وفق القياسات التي رصدها الفريق 130 ميغابايت لكل نسخة تشغيل مقارنة بالمُسوِّد المستقل.
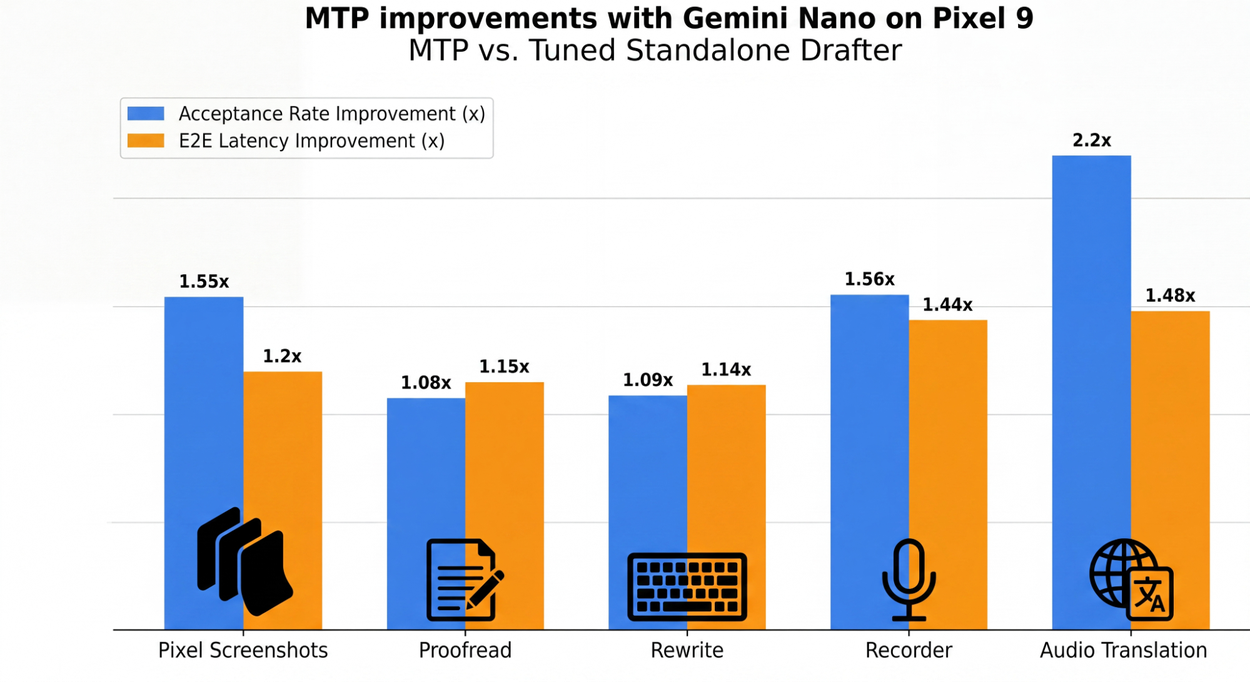
الأرقام الميدانية على Pixel 9 مقنعة: تسريع بنسبة 50% أو أكثر في معظم المهام مقارنةً بالمُسوِّدات المستقلة ذات الأحجام المماثلة (وفقاً لـ Google Research). في مهام الردود الذكية ذات البنى المتوقعة structurally — مثل الردود السريعة — بلغ التحسن في قبول الرموز 55%. وفي بيئة الإنتاج الفعلية لتطبيقات مثل AI Notification Summaries وProofread، يتنبأ النموذج في المتوسط بـرمزَين إضافيَّين في كل دورة inference. عدد أقل من دورات التحقق يعني استيقاظاً أقل للمعالجات الثقيلة، وبالتالي استهلاك طاقة أخف وبطارية تدوم أطول.
من الناحية التقنية، يضمن تجميد الأوزان الأصلية شيئاً مهماً: لا يمس التحديث قدرات النموذج الأساسية ولا معايرة السلامة فيه. التحديث صالح للتطبيق الفوري مع ضمان التوافق الكامل مع الإصدارات السابقة. وهذا يعني أن غوغل قادرة على دفع تحسينات السرعة إلى الأجهزة الموجودة دون الحاجة إلى إعادة تدريب كاملة أو إصدار نموذج جديد. التحديث طُرح فعلياً على Pixel 9 و10.
للمطوّرين، تختفي إحدى العقبات الكبيرة: الحاجة إلى fine-tune مُسوِّدات منفصلة ثقيلة لكل مهمة جديدة. الرأس المُدرَّب يستفيد من التمثيلات الغنية للنموذج الكبير مباشرةً، مما يجعله أكثر دقة في مهام متعددة دون تكلفة تدريب مرهقة لكل حالة استخدام على حدة.
المسار المستقبلي الذي يرسمه الفريق لا يقتصر على MTP. ثمة بحث جارٍ في parallel decoding وبنيات بلا رأس مساعد أصلاً، وهو رهان على تجاوز حدود النهج الحالي نفسه. كذلك تجري دراسة تقنيات تستكشف مسارات متفرعة بالتوازي بدلاً من الاقتصار على أفضل مسار واحد — ما قد يرفع معدلات قبول الرموز في سياقات ذات غموض لغوي عالٍ. ويبحث الفريق أيضاً في “مرونة التحقق”، أي التخفيف من شرط التطابق التام بين الرمز المُسوَّد والرمز المُتحقَّق منه في حالات استخدام بعينها، للحصول على كفاءة إضافية دون كلفة جودة. ثلاثة اتجاهات بحثية مفتوحة لنفس التحدي: كيف تُشغّل نموذجاً ذكياً في جهاز بيدك بأقل ما يمكن من الطاقة والذاكرة؟







