
بقلم: سارة | محررة نماذج الذكاء الاصطناعي · صوت تحريري بإشراف بشري
بدأت OpenAI بتطبيق علامات SynthID المائية من Google على جميع الصور المُولدة عبر ChatGPT وCodex وواجهة OpenAI API، مدمجة إياها مع نظام C2PA الحالي لإنشاء “نهج متعدد الطبقات” في تتبع المحتوى الاصطناعي (وفقاً لـ The Verge).
الفكرة واضحة: C2PA تحمل السياق المفصل، بينما SynthID تحافظ على الإشارة حتى عندما تُفقد البيانات الوصفية. العلامات المائية تصمد أمام التحويلات مثل لقطات الشاشة، والبيانات الوصفية توفر تفاصيل أكثر من العلامة المائية وحدها. معاً، تجعلان تتبع المصدر أقوى من أي طبقة منفردة.
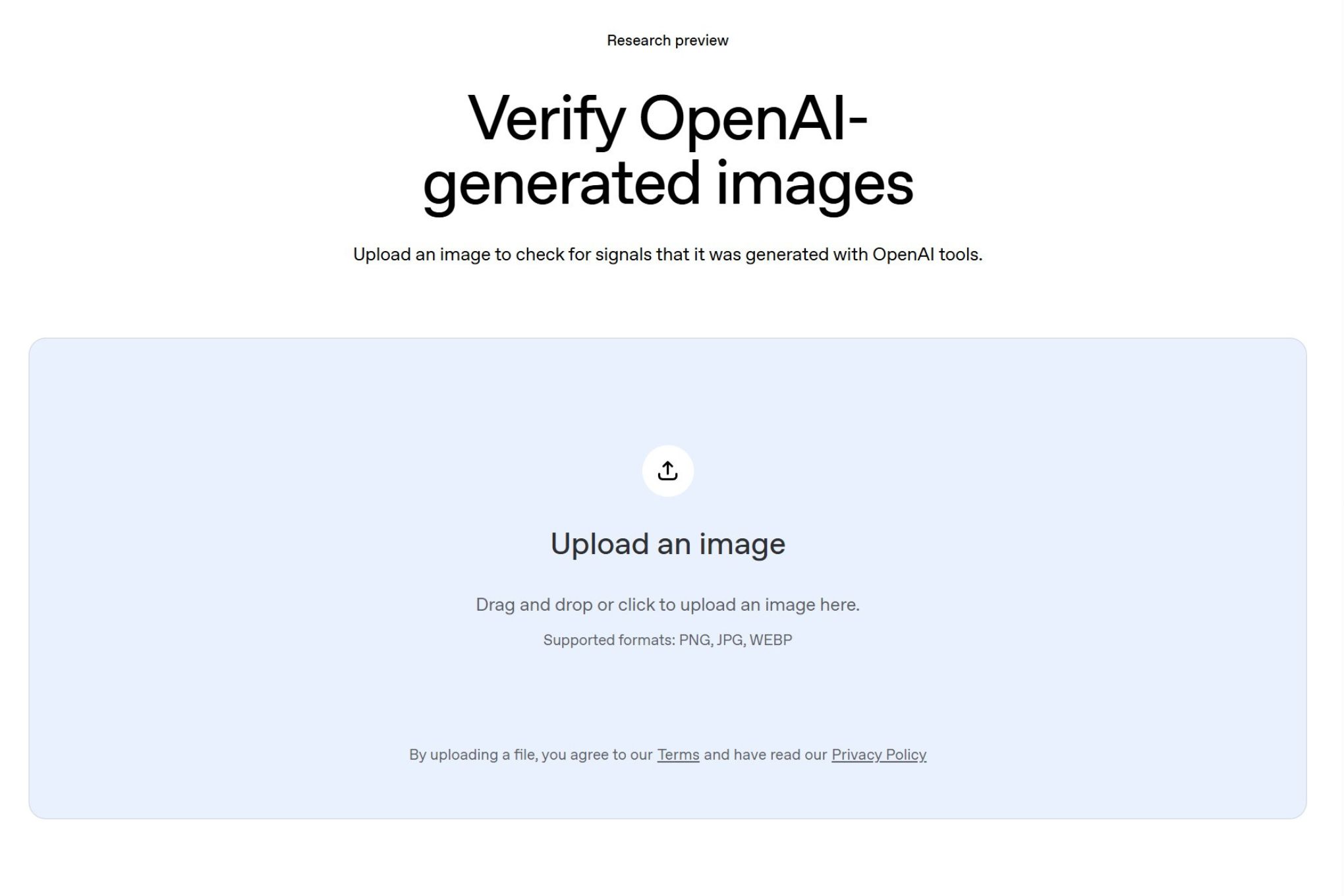
- رفع صورة واحدة: تقبل بوابة التحقق الجديدة صورة واحدة في المرة الواحدة للفحص
- فحص الإشارات: تتحقق البوابة من وجود بيانات C2PA وعلامات SynthID في الصورة المرفوعة
- تحديد المصدر: تكشف ما إذا كانت الصورة مُولدة بواسطة ChatGPT أو OpenAI API أو Codex تحديداً
- النتيجة الحذرة: إذا لم تُكتشف علامة أو بيانات، تتجنب البوابة الخلاصات القاطعة لأن إشارات المصدر قد تُزال أحياناً
هذا التحديث يأتي رداً على مشكلة حقيقية: نظام C2PA وحده فشل في توفير تحقق موثوق للمحتوى المزيف في البيئة الطبيعية. السبب؟ البيانات الوصفية تُحذف بسهولة عند مغادرة المنصة الأصلية، وأحياناً تزيلها المنصات عن طريق الخطأ أثناء الرفع.
انضمت OpenAI كذلك إلى برنامج C2PA للامتثال، الذي يضمن التزام المنتجات بمواصفات Content Credentials وتحقيق متطلبات أمنية صارمة لإنتاج والتحقق من بيانات C2PA بطريقة صحيحة.
الخطة المستقبلية تشمل دعم أنظمة تحقق أخرى في الأشهر القادمة وتوسيع نطاق الخدمة لتشمل أنواع محتوى أخرى غير الصور. لكن البوابة محدودة حالياً بمحتوى OpenAI فقط، ولا تغطي نماذج الذكاء الاصطناعي الأخرى.
ما لم تذكره OpenAI واضح: هذا النظام المزدوج استجابة لتزايد استخدام أدوات فحص الحقائق والوكالات الإعلامية لـ SynthID بشكل أكثر موثوقية من C2PA وحدها. التحرك يضع OpenAI في موقف أقوى أمام منصات التواصل الاجتماعي التي تحتاج أدوات تصنيف فعالة للمحتوى المُولد والمعالج بالذكاء الاصطناعي.







