بقلم: يوسف | محرر أدوات الذكاء الاصطناعي · صوت تحريري بإشراف بشري
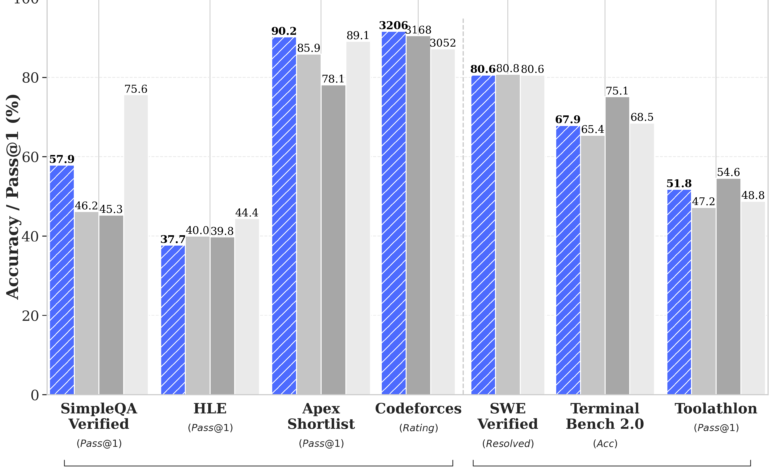
DeepSeek الصينية تضرب بقوة في قلب سوق الذكاء الاصطناعي العالمي. النسخ التجريبية من نماذج V4 Flash وV4 Pro تحقق أداءً يضاهي أقوى النماذج المغلقة في العالم بأسعار تقل ستة أضعاف عن منافسيها الأمريكيين.
التفاصل التقنية تكشف طموحاً لا يُستهان به. V4 Pro يحمل 1.6 تريليون معامل إجمالي مع تشغيل 49 مليار معامل، مما يجعله أكبر نموذج مفتوح الأوزان حتى اليوم (وفقاً لـ DeepSeek). النسخة الأصغر V4 Flash تضم 284 مليار معامل مع تشغيل 13 مليار، والاثنان يدعمان نافذة سياق تصل إلى مليون رمز — مساحة كافية لتحليل قواعد أكواد ضخمة أو مستندات طويلة في استعلام واحد.
النماذج تبرع في معايير التفكير المنطقي والبرمجة، وتقترب من أداء النماذج الرائدة أو تتفوق عليها في بعض المعايير. لكن نقطة الضعف تكمن في المعايير المعرفية التقليدية، والنماذج تدعم النصوص فقط دون الوسائط المتعددة حالياً.
المستخدمون يمكنهم تجربة النماذج عبر chat.deepseek.com من خلال وضعي Expert Mode أو Instant Mode. الوصول مباشر ومجاني للاختبار، مما يسمح للمطورين بتقييم الأداء قبل اتخاذ قرارات التكامل.
الفجوة الضيقة في الأداء مقابل الفارق الهائل في السعر تطرح تساؤلات جذرية حول استدامة النماذج التجارية للشركات الأمريكية. إذا استطاعت DeepSeek تقديم 90% من أداء GPT-4 بـ 15% من تكلفته، فإن معادلة التنافس في السوق قد تتغير بشكل جذري. السؤال ليس عن قدرة الصين على اللحاق، بل عن قدرة أمريكا على الحفاظ على هامش ربحها.







