بقلم: يوسف | محرر أدوات الذكاء الاصطناعي · صوت تحريري بإشراف بشري
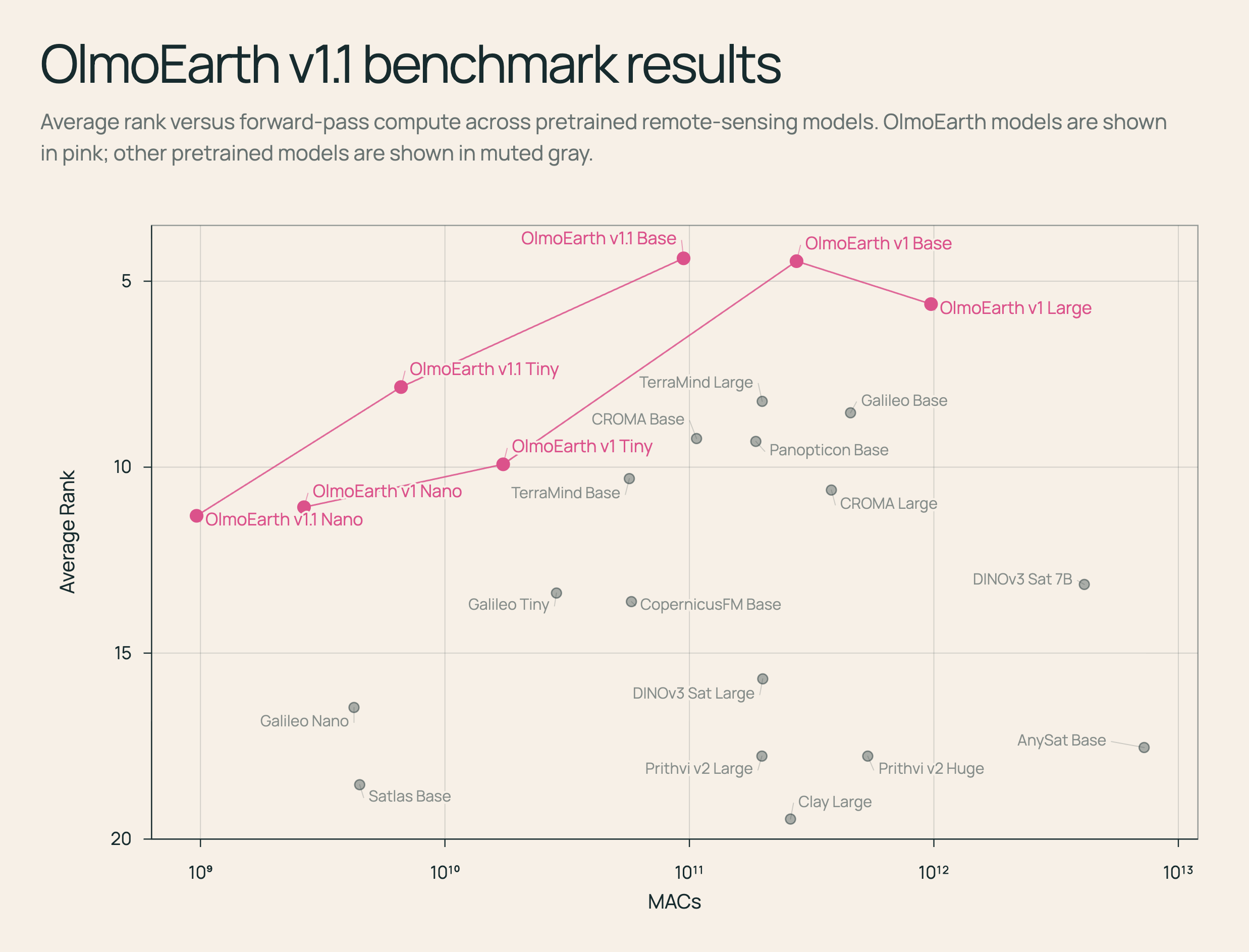
حقق معهد ألن للذكاء الاصطناعي اختراقاً في كفاءة نماذج الاستشعار عن بُعد مع إطلاق OlmoEarth v1.1، الذي يخفض تكاليف الحوسبة حتى 3 مرات مع الحفاظ على نفس مستوى الأداء في تحليل صور الأقمار الصناعية (وفقاً للتقرير التقني).
المشكلة الأساسية كانت في طول تسلسل الرموز المميزة. عندما يعالج OlmoEarth صور Sentinel-2، يحول البيانات إلى رموز يمكن للنموذج فهمها. النهج التقليدي يتطلب رمزاً منفصلاً لكل مستوى دقة مكانية (10 متر، 20 متر، 60 متر)، مما يعني 6 رموز لكل رقعة في حالة وجود خطين زمنيين. هذا التضاعف يرفع التكلفة الحاسوبية بشكل تربيعي لأن نماذج المحول تتطلب عمليات حسابية تتناسب مع مربع طول التسلسل.
الحل الجذري جاء من إعادة تصميم طريقة تمثيل الرموز. بدلاً من 3 رموز منفصلة لكل دقة مكانية، يدمج v1.1 جميع البيانات في رمز واحد لكل رقعة زمنية. هذا التغيير يبدو بسيطاً لكنه معقد تقنياً – الدمج المباشر أدى لانخفاض 10 نقاط مئوية في معيار m-eurosat kNN. السبب أن الفصل بين الأطياف المختلفة يساعد النموذج على تعلم العلاقات بين الموجات الطيفية المختلفة، وهي علاقات حاسمة لتمييز أنواع الغطاء النباتي والتغيرات البيئية.
لحل هذه المعضلة، طور الفريق نظام تدريب مسبق محدث يحافظ على هذه العلاقات الطيفية الحرجة رغم دمج الرموز. النتيجة نموذج أكثر كفاءة بـ3 مرات مع نفس الأداء تقريباً، مع بعض حالات التراجع الطفيف التي يوثقها التقرير التقني بشفافية.
الأثر العملي لهذا التحسن كبير. منذ إطلاق الإصدار الأول في نوفمبر 2025، استخدمت الجهات الشريكة OlmoEarth في تتبع تغيرات أشجار المانجروف، تصنيف أسباب فقدان الغابات، وإنتاج خرائط أنواع المحاصيل على مستوى دول كاملة في أيام معدودة. لكن التكلفة الحاسوبية كانت العائق الأكبر أمام توسيع هذه التطبيقات.
التحدي الأساسي أن معالجة صور الأقمار الصناعية على نطاق قاري أو عالمي تتطلب استنتاجاً عبر عشرات أو مئات الآلاف من الكيلومترات المربعة. دورة الحياة الكاملة – تصدير البيانات، المعالجة المسبقة، الاستنتاج، والمعالجة اللاحقة – تستهلك موارد حاسوبية ضخمة، والحوسبة هي التكلفة الأعلى في المنظومة بأكملها.
النموذج الجديد متاح بثلاثة أحجام: Base وTiny وNano، ويمكن للمطورين تحميل الأوزان والكود المصدري مجاناً. الفريق ينصح المستخدمين الحاليين بتجربة v1.1، لكن مع اختبار دقيق لمهامهم المحددة نظراً لوجود بعض حالات التراجع في الأداء.
ما يميز هذا البحث أن الفريق دّرب النموذج الجديد على نفس مجموعة البيانات المستخدمة في v1، مما يعزل تأثير التغييرات المنهجية ويساعد المجتمع العلمي على فهم المبادئ الأساسية لتدريب نماذج الاستشعار عن بُعد بشكل أفضل.