بقلم: ليلى | محررة أدوات المطورين · صوت تحريري بإشراف بشري
أطلقت مختبرات DeepReinforce عائلة نماذج مفتوحة المصدر باسم Ornith-1.0، مُصمَّمة خصيصاً للبرمجة الوكيلية (agentic coding)، وتتميّز بقدرة غير مسبوقة في نماذج المصدر المفتوح: إنّها لا تكتفي بحلّ المهام، بل تبني السقالات التنظيمية (scaffolds) التي توجّه عملها بنفسها، دون تدخّل بشري في تصميم تلك السقالات.
تأتي العائلة بأربعة إصدارات تغطّي طيفاً واسعاً من الاحتياجات: نموذج 9B Dense مُحسَّن للنشر على الحافة (edge deployment)، ونموذج 31B Dense للاستخدام المتوازن، ونموذج 35B MoE للسيناريوهات متوسطة الحجم، وصولاً إلى العملاق 397B MoE المُستهدَف للأعمال على مستوى الحدود التقنية. جميع الإصدارات مبنيّة فوق أُسس مُدرَّبة مسبقاً من Gemma 4 وQwen 3.5، (وفقاً لـ Testing Catalog).
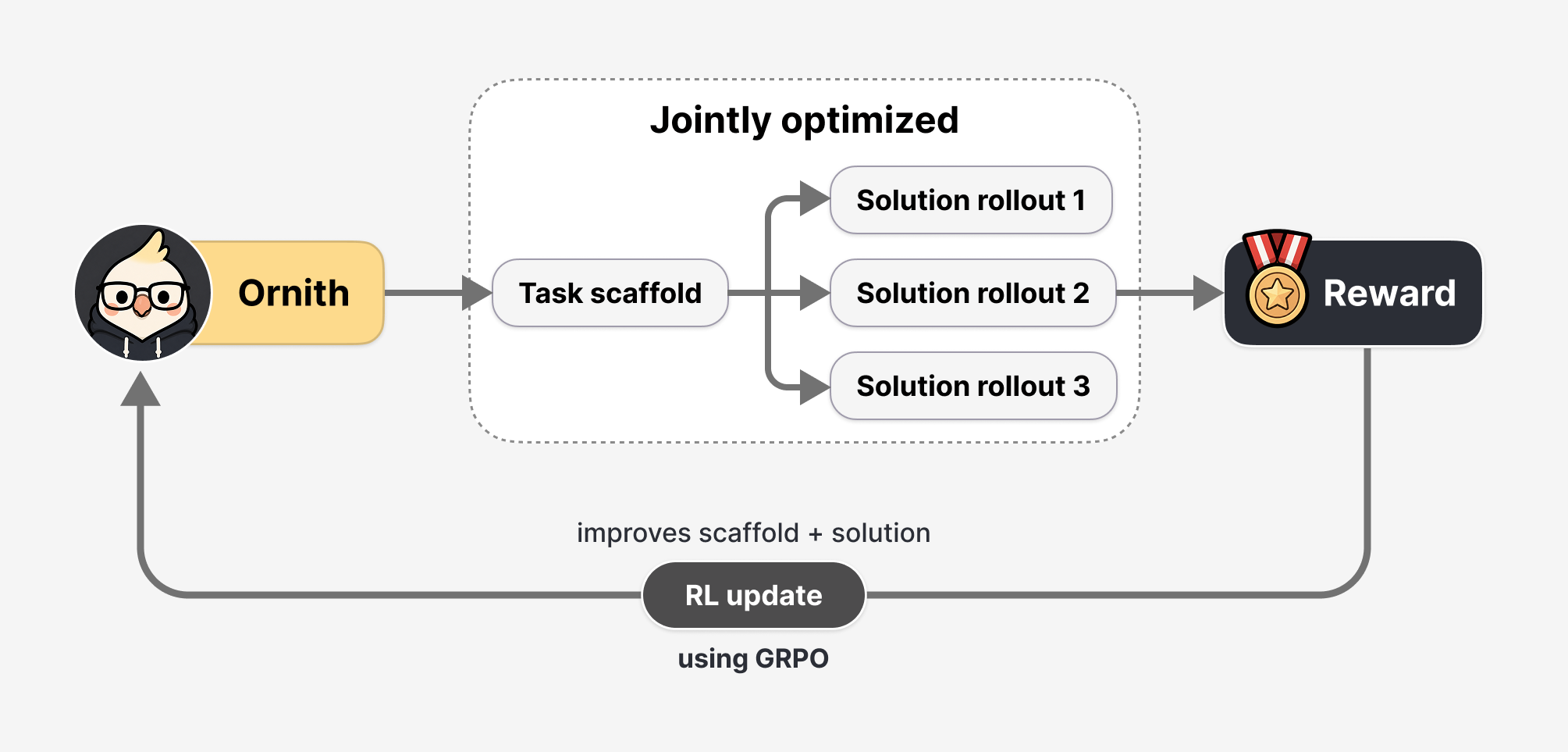
الفكرة الجوهرية تكمن في آلية التعلم بالتعزيز المُعتمَدة. كلّ خطوة تدريبية تنقسم إلى مرحلتين: تُقترح أولاً سقالة مُحسَّنة بناءً على المهمة والسقالة السابقة المستخدمة معها، ثم يُولَّد الحلّ مشروطاً بتلك السقالة الجديدة. المكافأة الناتجة عن الحلّ تتدفق للخلف إلى كلا المرحلتين، ما يجعل النموذج يتعلّم صياغة التنظيم والإجابة في آنٍ واحد. ومع تكرار هذه الدورات، تتحوّر السقالات وتُنتخب تلك التي تُنتج مسارات أعلى مكافأةً، فتبرز استراتيجيات مُخصَّصة لكلّ نوع من المهام تلقائياً.
لكنّ السماح للنموذج بكتابة سقالاته الخاصة يُفتح معه خطر التلاعب بالمكافأة (reward hacking)، أي أن تُصمَّم السقالة لإرضاء المُتحقِّق دون إنجاز المهمة فعلاً. للتصدي لهذا، تعتمد DeepReinforce نظام دفاع ثلاثي الطبقات:
- حدٌّ خارجي ثابت يُبقي البيئة واختبارات العزل بعيدةً تماماً عن متناول النموذج.
- مُراقِب حتمي يرصد أي محاولة للوصول إلى مسارات محجوبة أو تعديل نصوص التحقق.
- قاضٍ لغوي مُجمَّد يُبطل نتائج المُتحقِّق متى رصد تلاعباً داخل السطح المسموح به من الأدوات.
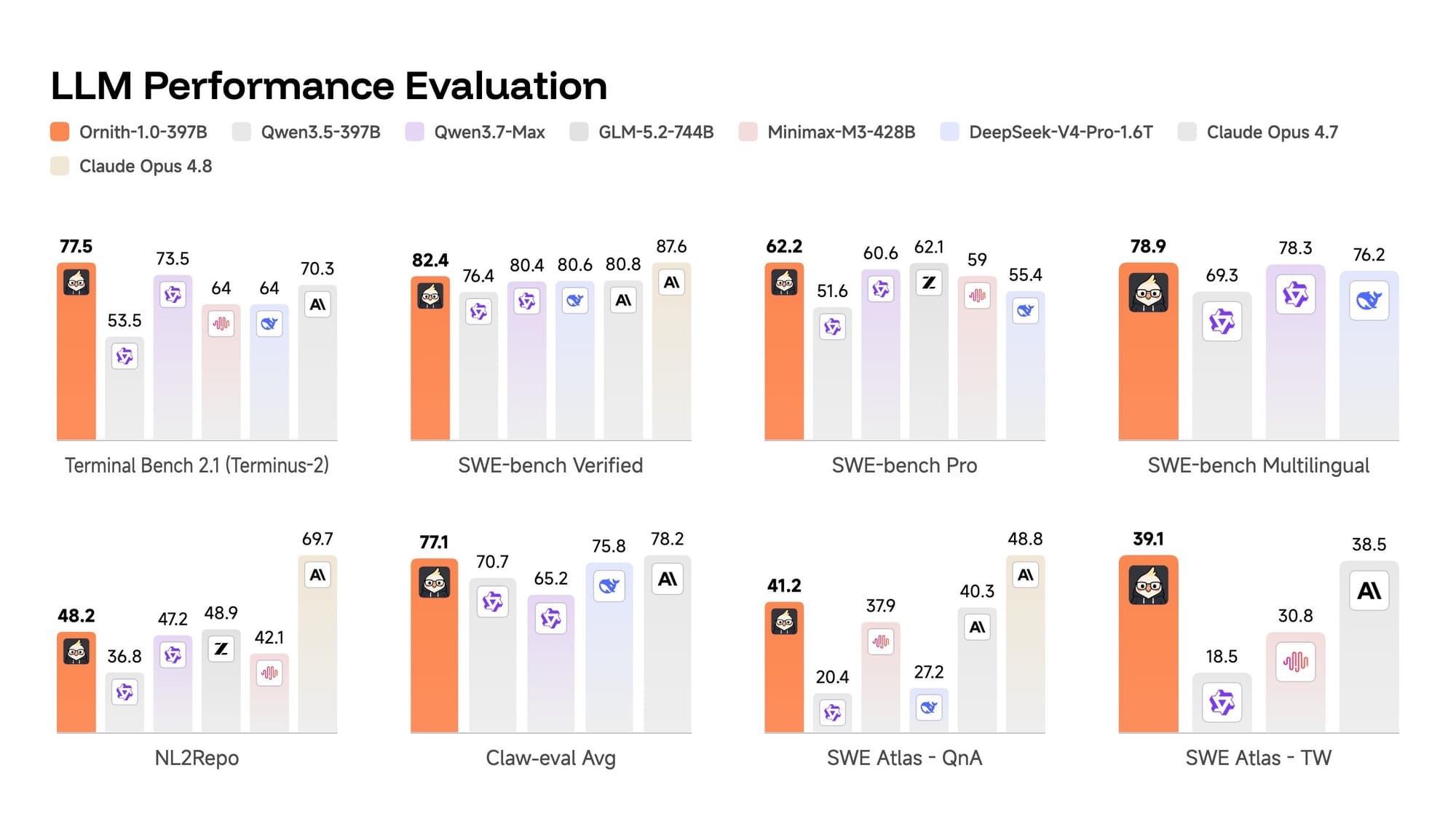
على صعيد الأداء، تُضع DeepReinforce Ornith-1.0 في مرتبة الصدارة بين النماذج المفتوحة المكافئة الحجم. النموذج الرائد 397B يسجّل 77.5 على معيار Terminal-Bench 2.1 و82.4 على SWE-Bench Verified، (وفقاً لـ Testing Catalog) — أرقام تُقارن، بحسب الشركة، بأداء Claude Opus 4.7 وتتفوّق على نظرائه المفتوحين من أمثال MiniMax M3 وDeepSeek-V4-Pro. أمّا نموذج 35B فيتجاوز نظراءه من Qwen وGemma بالحجم نفسه، فيما يُسجّل النموذج الأصغر 9B درجة 43.1 على Terminal-Bench 2.1 و69.4 على SWE-Bench Verified — مُقارِباً بذلك نماذج أضخم بكثير كـ Gemma 4-31B، ما يجعل قدرات البرمجة المتقدمة في متناول الأجهزة المحدودة الموارد.
هذا الإصدار يتواصل مع مسيرة DeepReinforce في أبحاث التعلم بالتعزيز المفتوحة، التي شملت سابقاً CUDA-L1 وحلقة التحسين IterX لوكلاء الكود. Ornith-1.0 يمضي خطوةً أبعد بدمج بناء السقالات ضمن عملية التدريب ذاتها، لا كطبقة تُضاف فوقها. الأوزان والتقرير التقني متاحان الآن على Hugging Face لأي فريق يرغب في تشغيل النماذج أو دراستها مباشرة.
السؤال الذي يبقى مفتوحاً هو مدى متانة نظام الدفاع الثلاثي في بيئات إنتاجية حقيقية بعيداً عن الاختبارات المُتحكَّم بها. النماذج التي تكتب تنظيمها الخاص تمثّل نقلةً نوعية في بنية الوكلاء، لكنّ هامش الثقة سيُحدّده المجتمع المفتوح حين يبدأ التدقيق الفعلي في الأوزان والتقارير.