بقلم: يوسف | محرر أدوات الذكاء الاصطناعي · صوت تحريري بإشراف بشري
PP-OCRv6 هو أحدث جيل من عائلة نماذج OCR الشاملة من PaddleOCR، ويُقدّم ثلاث طبقات من النماذج تبدأ من 1.5M معامل وتصل إلى 34.5M معامل، مع دعم 50 لغة في نموذج واحد موحّد — من الصينية المبسّطة والتقليدية والإنجليزية واليابانية إلى 46 لغة ذات خط لاتيني. الهدف ليس بناء أكبر نموذج ممكن، بل تقديم OCR دقيق وخفيف يمكن نشره فعلاً في بيئات إنتاجية حقيقية.

على المعايير الداخلية متعددة السيناريوهات لـ PaddleOCR، (وفقاً لـ PaddleOCR Blog) يحقق النموذج المتوسط PP-OCRv6_medium دقة كشف Hmean بنسبة 86.2%، ودقة تعرّف تبلغ 83.2%، وهو ما يمثّل تحسناً بمقدار 4.6 نقطة مئوية في الكشف و5.1 نقطة في التعرّف مقارنةً بالإصدار السابق PP-OCRv5_server.
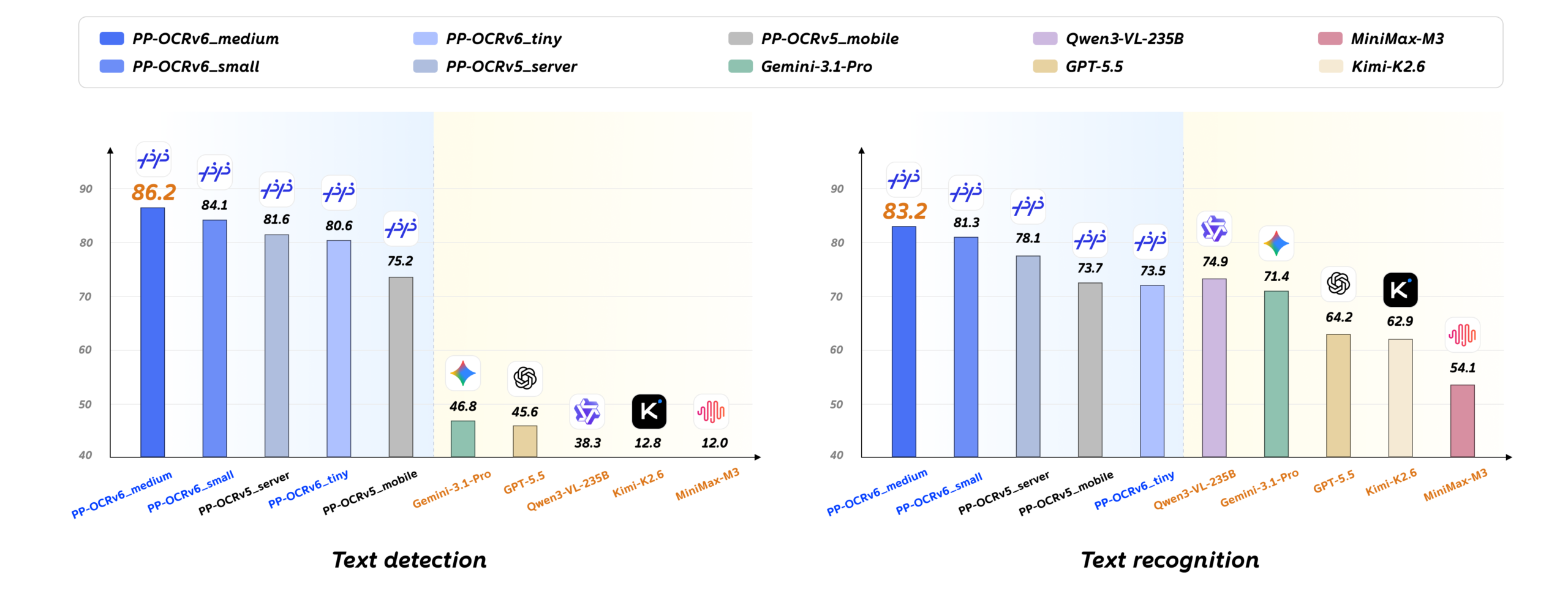
العائلة مقسّمة إلى ثلاث طبقات لكل منها حالة استخدام مختلفة: النموذج Tiny بـ1.5M معامل يناسب الأجهزة الطرفية والبيئات المحدودة الموارد مع دقة كشف 80.6% وتعرّف 73.5%؛ النموذج Small بـ7.7M معامل مخصص للهاتف المحمول وخدمات OCR المتوازنة مع دقة كشف 84.1% وتعرّف 81.3%؛ أما Medium بـ34.5M معامل فهو للخوادم والخطوط الصناعية وإدخال المستندات بأعلى دقة متاحة. الطبقتان Medium وSmall تدعمان الـ50 لغة، بينما Tiny مخصص للنشر الخفيف.

معمارياً، يعتمد PP-OCRv6 على عمود فقري موحّد هو PPLCNetV4 لمرحلتَي الكشف والتعرّف معاً، وهو ما يمنح العائلة تماسكاً هندسياً بدلاً من كونها نماذج منفصلة بلا رابط. في مرحلة الكشف، يُضاف RepLKFPN وهو شبكة هرمية خفيفة ذات نوى كبيرة مصممة للكشف متعدد المقاييس، وتُعالج النصوص الصغيرة والمدوّرة والكثيفة في الخلفيات المعقّدة. أما التعرّف فيُعالجه EncoderWithLightSVTR الذي يجمع النمذجة المحلية مع الانتباه العالمي لتحسين الدقة على نصوص الشاشات والرموز الصناعية والأحرف المتعددة اللغات.
من الناحية العملية، يُشغَّل PP-OCRv6 عبر ثلاثة backends مختلفة من خلال PaddleOCR 3.7 بواجهة موحّدة: Paddle Inference الأصلي، وTransformers لبيئات Hugging Face وPyTorch، وONNX Runtime للنشر المحمول. هذا يعني أنك تستطيع اختيار runtime يناسب بيئتك دون تغيير النموذج ذاته. للبدء بالنموذج الافتراضي Medium مع Paddle Inference:
- ثبّت PaddleOCR بالأمر:
pip install paddleocr - استورد
PaddleOCRوأنشئ كائن OCR مع إيقاف تصنيف اتجاه المستند وإزالة التشويه:ocr = PaddleOCR(use_doc_orientation_classify=False, use_doc_unwarping=False, use_textline_orientation=False) - مرّر الصورة إلى
ocr.predict("رابط_الصورة")والنتيجة تعود كمصفوفة من المناطق النصية - احفظ النتائج كصورة باستخدام
res.save_to_img("output")أو كـ JSON منظّم بـres.save_to_json("output") - للتبديل إلى Transformers backend، أضف
engine="transformers"عند إنشاء الكائن - للتبديل إلى ONNX Runtime، استخدم
engine="onnxruntime"— مع توافر نماذج ONNX في مجموعة PP-OCRv6 على Hub
المخرجات المنظّمة بصيغة JSON قابلة للتوصيل مباشرةً بأنظمة downstream كـRAG وتحليل المستندات ومحركات البحث والوكلاء الذكيين. وهذا تحديداً ما يجعل PP-OCRv6 مختلفاً عن مجرد كونه أداة OCR: إنه يُصمَّم كمكوّن بنية تحتية يُغذّي تطبيقات أكثر تعقيداً، لا كحل مستقل. يمكنك تجربته مباشرةً عبر الديمو المباشر على Hugging Face قبل أي تكامل.
نقطة تستحق الانتباه: النموذج Tiny لا يدعم الـ50 لغة، وأرقام الدقة المُعلنة صادرة عن المعايير الداخلية لـPaddleOCR وليس عن معايير مستقلة طرف ثالث — وهو تمييز مهم عند المقارنة مع أدوات OCR أخرى في بيئتك الإنتاجية. كذلك تبقى اللغة العربية غائبة عن قائمة اللغات المدعومة حتى اللحظة، رغم أن 46 لغة لاتينية مشمولة.