
بقلم: ليلى | محررة أدوات المطورين · صوت تحريري بإشراف بشري
حققت شركة HCompany إنجازاً تقنياً يعيد تشكيل مشهد الوكلاء الذكية بإطلاق عائلة Holo3.1 – أول نماذج ذكاء اصطناعي مُحسَّنة للتشغيل المحلي مع الحفاظ على أداء متطور يضاهي الحلول السحابية.
المشكلة كانت واضحة: منذ إطلاق Holo3 في مارس الماضي، اكتشف المطورون أن الأداء القوي في بيئة واحدة لا ينتقل بالضرورة إلى أخرى. الأجهزة المحمولة وأطر عمل الوكلاء البديلة وبيئات التنفيذ المختلفة – كل منها يُدخل مصادر جديدة لتدهور الأداء.
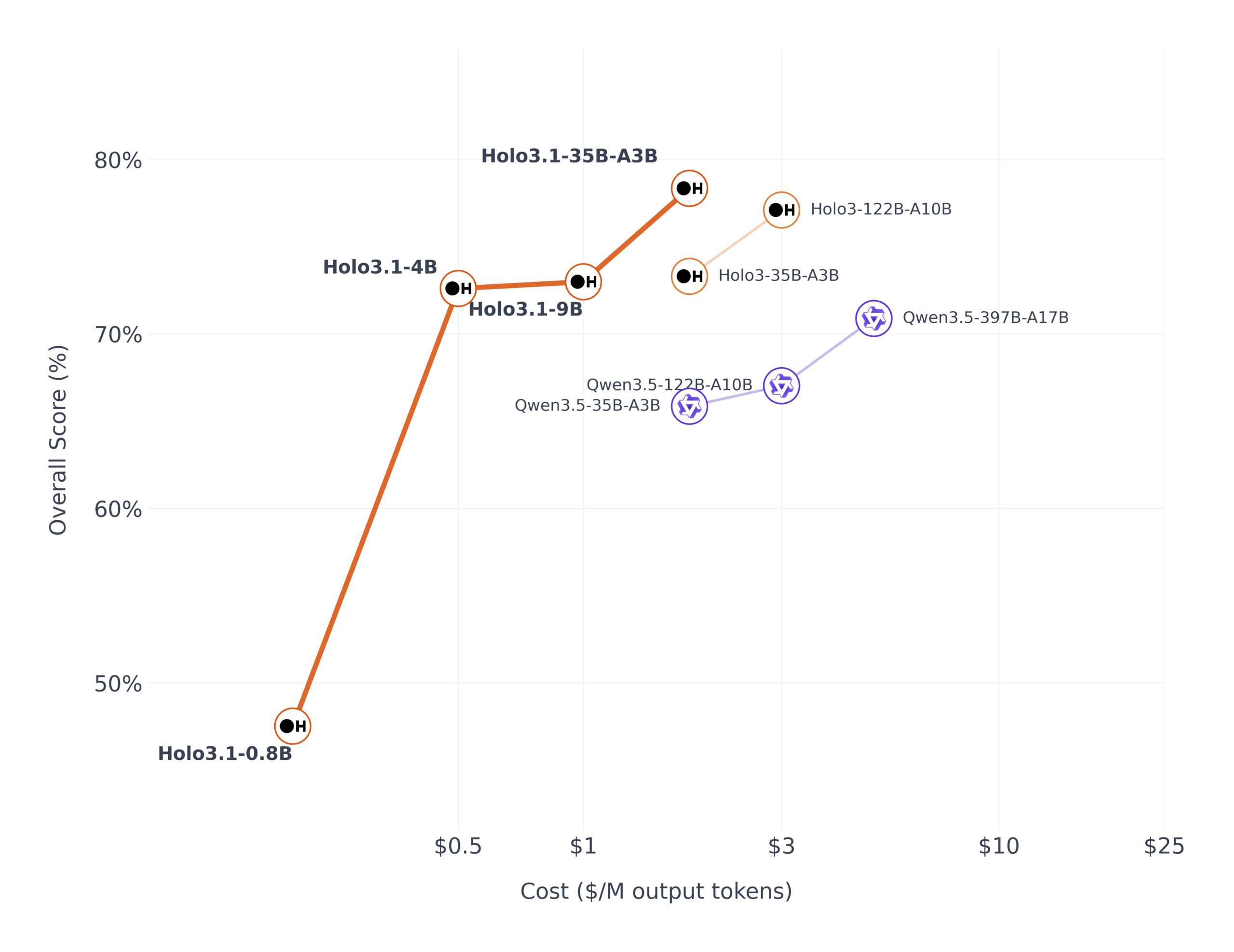
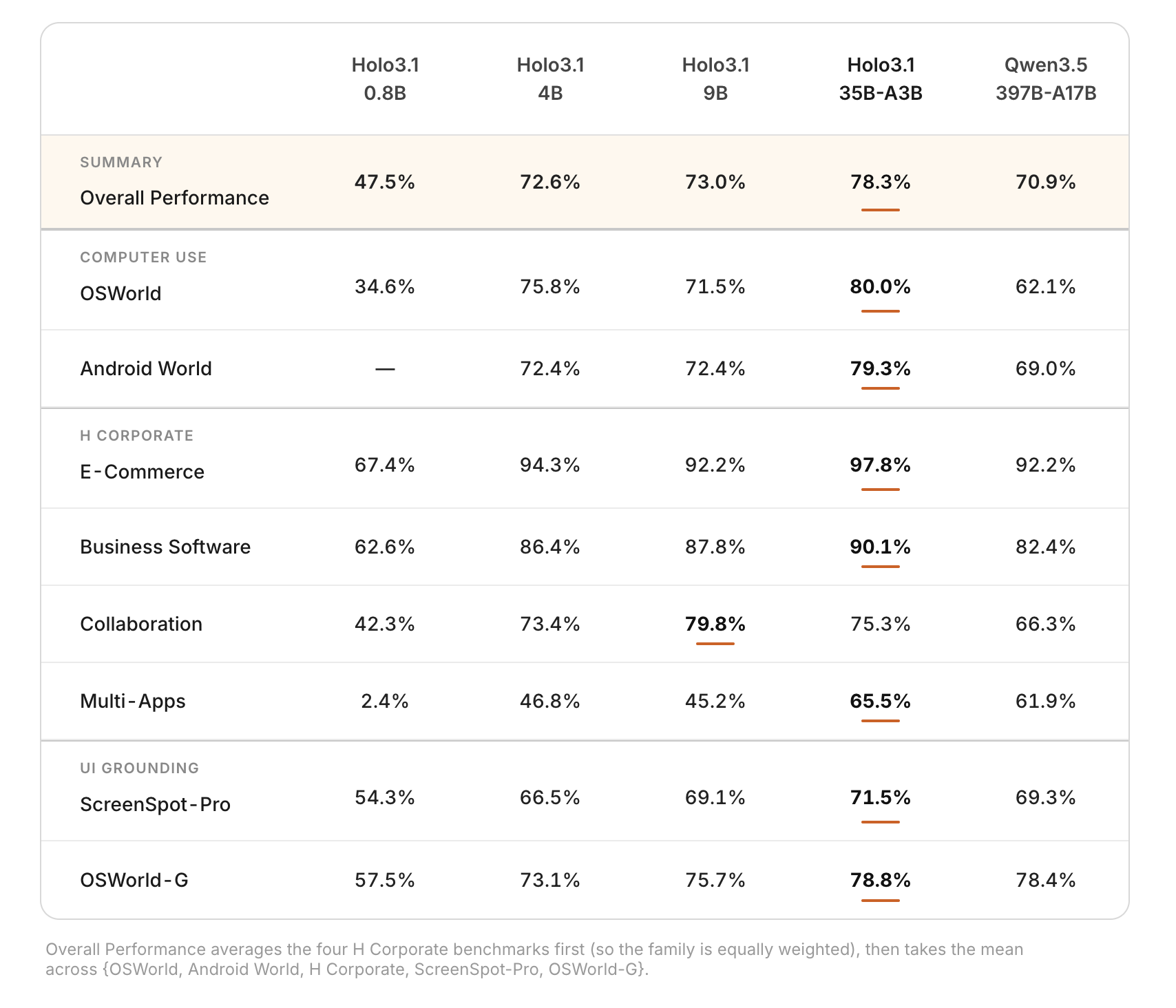
- قفزة جذرية في أداء الأجهزة المحمولة: على معيار AndroidWorld، قفز نموذج 35B-A3B من 67% إلى 79.3% (وفقاً لـ HCompany)، بينما حققت النماذج الأصغر 4B و9B تحسناً من 58% إلى 72%. هذا يعني أن تطبيقات الأندرويد باتت قابلة للأتمتة بكفاءة مماثلة لأنظمة سطح المكتب.
- توافق شامل مع أطر عمل الوكلاء: دعم جديد لبروتوكولات استدعاء الدوال إلى جانب مخرجات JSON المنظمة يحقق تكافؤاً في الأداء بين طرق التنفيذ المختلفة. النتيجة: تحسن بـ 25% في أداء منتج Holotab (وفقاً لـ HCompany).
- إصدارات محسنة للاستدلال المحلي: لأول مرة تطلق الشركة أوزان مُحسَّنة بصيغ FP8 و Q4 GGUF و NVFP4. إصدارات FP8 و NVFP4 تحقق نفس نقاط OSWorld مع انخفاض طفيف – نقطتين فقط – مقارنة بالنسخة كاملة الدقة BF16.
- تسريع مركب يكسر حاجز السرعة: على DGX Spark، يحقق NVFP4 W4A16 معدل إنتاجية رمزية أعلى بـ 1.41× من FP8 و1.74× من BF16 (وفقاً لـ HCompany). التحسينات المركبة تحقق تسريعاً شاملاً بالضعف تقريباً، مخفضة متوسط وقت الخطوة من 6.8 ثانية إلى 3.3 ثانية.
- أحجام متدرجة للاحتياجات المختلفة: أربعة أحجام – Holo3.1-0.8B للوكلاء خفيفة الوزن، 4B للنشر فعال التكلفة، 9B للتوازن بين الأداء وزمن الاستجابة، و35B-A3B للأداء المتطور.
- نشر محلي على أجهزة المستهلكين: إصدارات Q4 GGUF محسنة لأجهزة Windows وMac مع أرقام مرجعية لشرائح Apple Silicon. التنفيذ يبقى محلياً تماماً دون خروج بيانات من شبكة المستخدم.
 Qwen 3.5″>
Qwen 3.5″>التطبيق العملي يكشف تفاصيل مهمة: معدل طلبات الوكيل على DGX Spark يُظهر أن vLLM مع NVFP4 يحقق أعلى معدل في الوضعين العادي والسريع، متفوقاً على Q4 GGUF و FP8. هذه التحسينات ستُدمج في إطار عمل سطح المكتب القادم من الشركة.
لكن التقدم لا يأتي بلا تحديات. الذاكرة وقوة المعالجة تبقيان قيدين حقيقيين للنماذج المحلية مقارنة بالحلول السحابية. النماذج الأصغر، رغم سرعتها المثيرة، تفتقر لبعض القدرات المعقدة التي توفرها النماذج الأكبر.
السؤال الأهم: هل نشهد بداية نهاية عصر الاعتماد على الخدمات السحابية للوكلاء الذكية؟ الأرقام تشير لهذا الاتجاه، خاصة للمؤسسات التي تضع الخصوصية في المقدمة.
المطورون المهتمون يمكنهم البدء فوراً عبر واجهة برمجة تطبيقات Holo Models أو تحميل النماذج من مجموعة Holo3.1 على Hugging Face.







