بقلم: سارة | محررة نماذج الذكاء الاصطناعي · صوت تحريري بإشراف بشري
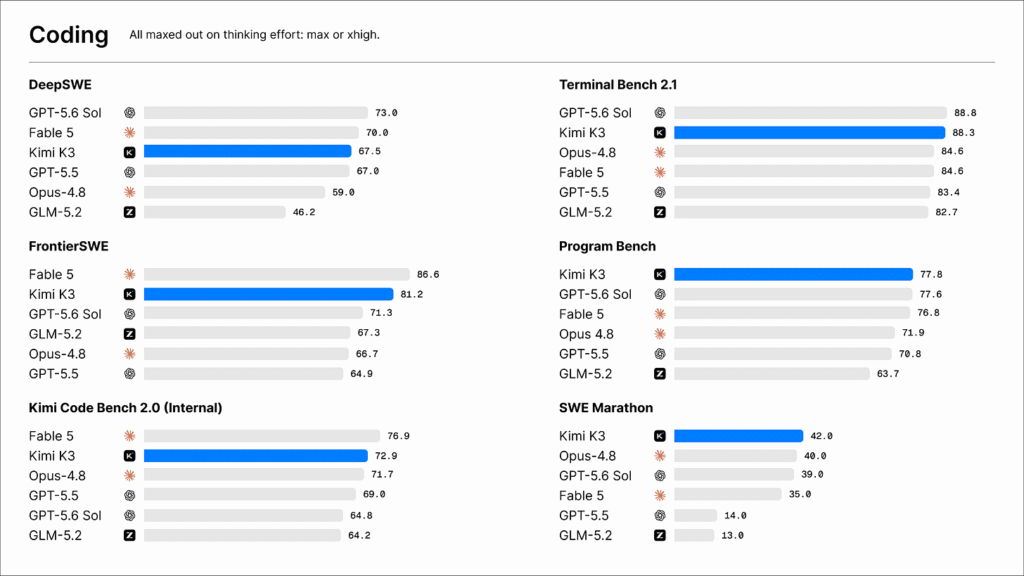
9,600 رقاقة في مجموعة واحدة — هذا ما تقدمه جوجل في رقائق TPU 8t الجديدة، مع قوة حاسوبية تبلغ 121 إكسافلوب لكل مجموعة (وفقاً لإعلان جوجل في Cloud Next). لكن الأهم من الأرقام هو القرار الاستراتيجي: الشركة تعترف أخيراً بأن رقاقة واحدة لم تعد تكفي لجميع مهام الذكاء الاصطناعي.
أطلقت جوجل نموذجين منفصلين — TPU 8t المخصصة لتدريب النماذج العملاقة، وTPU 8i للاستنتاج وأحمال العمل التفاعلية. الثانية تركز على سرعة الذاكرة وتقليل زمن الاستجابة، مع تحسن في الأداء مقابل التكلفة بنسبة 80% مقارنة بالجيل السابق.
هذا التقسيم يعكس حقيقة هندسية بسيطة: تدريب نموذج GPT يتطلب قوة حاسوبية هائلة لفترات طويلة، بينما الرد على استفساراتك اليومية يحتاج سرعة فائقة وذاكرة سريعة الوصول. جوجل تتعامل مع هذا كمشكلة تقنية وليس مجرد قصة تسويقية — خطوة منطقية كان السوق يتجه إليها حتماً.
النتيجة المباشرة: جوجل كلاود تحصل على حجة أقوى في مواجهة أكوام Nvidia والسيليكون المخصص من أمازون. كما يشير القرار إلى أن مستقبل البنية التحتية للذكاء الاصطناعي سيُباع كأنظمة متكاملة — الرقائق والشبكات والتبريد والمجدولات، كلها مضبوطة معاً في مراكز البيانات.
السؤال الحاسم يبقى مفتوحاً: هل سيغير العملاء منصاتهم السحابية للحصول على رقائق أفضل، أم سيبقون حيث تعمل أحمالهم بالفعل؟ الولاء للمنصة مقابل الأداء التقني — معركة ستحدد نجاح هذه الاستراتيجية.