بقلم: يوسف | محرر أدوات الذكاء الاصطناعي · صوت تحريري بإشراف بشري
بسطر استيراد واحد بدلاً من إعادة كتابة الكود بالكامل، حقّق NVIDIA NeMo AutoModel قفزةً تتراوح بين 3.4 و3.7 مرة في سرعة التدريب، مع توفير بين 29 و32% من ذاكرة GPU مقارنةً بـ HuggingFace Transformers v5 عند fine-tuning نماذج Mixture-of-Experts — وهذا ليس وعداً تسويقياً، بل نتيجة قياسات فعلية على أجهزة H100 (وفقاً لمدونة NVIDIA على HuggingFace).
المشكلة التي يحلّها هذا الإصدار ليست مجرد بطء — بل استحالة التشغيل. عند محاولة fine-tuning نموذج Nemotron 3 Ultra 550B A55B بمعاملاته الـ 550 مليار على Transformers v5، تنفد الذاكرة تماماً ولا تظهر أي نتيجة لتقارنها. NeMo AutoModel هو الأداة الوحيدة التي تجعل هذه العملية ممكنة أصلاً على 16 عقدة من H100 تضم 128 GPU.
 NVIDIA NeMo AutoModel مع HuggingFace Transformers”>
NVIDIA NeMo AutoModel مع HuggingFace Transformers”>لفهم لماذا هذا التحسين ضخم بهذا الشكل، يجب أن تعرف كيف تعمل نماذج MoE. بدلاً من تفعيل كل المعاملات لكل token، تُوجّه MoE كل token نحو مجموعة محدودة من “الخبراء” — مئات من الشبكات المتخصصة. هذا التوجيه يخلق تحديات جسيمة: توزيع tokens عبر عشرات الخبراء، دمج عمليات الضرب المصفوفي في kernel واحد، توزيع الأوزان عبر GPUs متعددة، وتداخل الاتصالات مع العمليات الحسابية — كل هذا يتجاوز ما يقدّمه أي مكتبة عامة. Transformers v5 أضافت دعماً أولياً لـ MoE مع expert backends وdynamic weight loading وtensor parallel plans، لكن NeMo AutoModel يأخذ هذا الأساس ويبني فوقه ثلاث طبقات تحسين مترابطة.
ما يميّز هذه المكتبة أن NeMoAutoModelForCausalLM يرث من AutoModelForCausalLM مباشرةً، لذا أي كود يعمل مع HuggingFace يعمل مع AutoModel بتغيير سطر الاستيراد فقط. بالنسبة لنماذج MoE الشائعة مثل Qwen3 وNVIDIA Nemotron وGPT-OSS وDeepSeek V3، تشحن المكتبة بتطبيقات مُحسّنة يدوياً تشمل TransformerEngine attention وfused linear layers وcustom expert kernels. للبقية، تعود إلى HuggingFace العادي مع بعض التحسينات كـ Liger kernel patching.
إليك كيف تبدو عملية fine-tuning نموذج Nemotron 3 Nano 30B A3B على 8 GPUs بـ Expert Parallelism كاملاً:
- تهيئة بيئة الـ distributed training: شغّل
dist.init_process_group(backend="nccl")لتفعيل NCCL وضبطtorch.cuda.set_deviceبناءً على متغيرLOCAL_RANK. - بناء distributed mesh بـ FSDP2 و EP=8: استخدم
create_distributed_setup_from_configمع تمرير{"strategy": "fsdp2", "ep_size": 8}لتوزيع أوزان الخبراء على الـ 8 GPUs. - تحميل النموذج بـ from_pretrained(): مرّر
distributed_setupمباشرةً للدالة — هذا كل ما تحتاجه لتفعيل Expert Parallelism وTransformerEngine وDeepEP dispatch دفعةً واحدة. - ضبط BackendConfig للتحكم الدقيق: حدّد
attn="te"لـ TransformerEngine attention، وlinear="te"للطبقات الخطية، وexperts="torch_mm"للـ grouped expert matmul، وdispatcher="deepep"لـ DeepEP fused all-to-all dispatch. - الحفظ بـ save_pretrained() بصيغة HuggingFace القياسية: النماذج المحفوظة متوافقة مع vLLM وSGLang مباشرةً، ما يعني أن ما تُدرّبه يمكن نشره بأدوات inference المعتادة دون تحويلات إضافية.
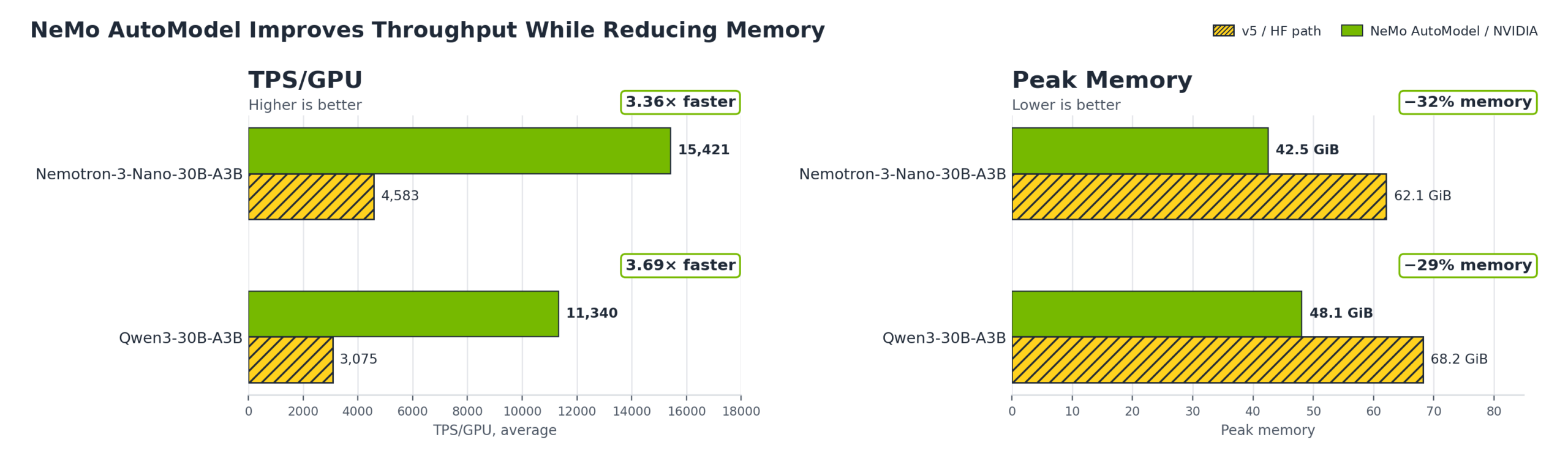
الأرقام التفصيلية تكشف أين يحدث التحسين بالضبط. على نموذج Qwen3-30B-A3B بعقدة واحدة (8x H100، sequence length 4096، local batch size 1)، انهار Transformers v4 بـ deadlock كامل بسبب مشكلة بنيوية: v4 يخزن خبراء Qwen3 كـ ModuleList من 128 وحدة MLP مستقلة لكل منها FSDP wrapper، فعندما يتلقى كل rank بيانات مختلفة، تتخطى ranks مختلفة خبراء مختلفين مما يُنتج AllGather/ReduceScatter collectives غير متطابقة وتجميداً لا نهائياً. Transformers v5 حلّ هذه المشكلة بتخزين الخبراء كـ tensors ثلاثية الأبعاد موحدة، ووصل إلى 3,075 TPS/GPU بذاكرة ذروة 68.2 GiB. NeMo AutoModel وصل إلى 11,340 TPS/GPU بذاكرة 48.1 GiB فقط — تسارع 3.69× وتوفير 29% من الذاكرة. الفارق في الـ backward pass وحده: 758ms في v5 مقابل 178ms في NeMo AutoModel، أي تسارع 4.26×.
على Nemotron 3 Nano 30B A3B — وهو نموذج هجين يدمج Mamba2 وLatentMoE وMulti-Token Prediction — كان v4 يعمل (لأن كود hub الخاص بـ NVIDIA يُشغّل جميع الخبراء بغض النظر عن token assignment)، لكنه بطيء بشكل لافت: 1,807 TPS/GPU. رفعه v5 إلى 4,583 TPS/GPU مع ذاكرة 62.1 GiB. NeMo AutoModel بلغ 15,421 TPS/GPU مع ذاكرة 42.5 GiB فقط — تسارع 3.36× على v5 وتوفير 32% من الذاكرة. زمن الـ backward pass انخفض من 611ms إلى 157ms.
أما على مستوى النماذج الضخمة، فإن Nemotron 3 Ultra 550B A55B الذي يُدرَّب بـ full fine-tuning (كل معامل يُحدَّث، حالة Adam optimizer تُحسب كاملاً) على 16 عقدة H100 — 128 GPU — يُسجّل 815 TPS/GPU بمعدل 293 TFLOP/s/GPU وذاكرة ذروة 58.2 GiB. لا يوجد رقم مقارن لـ v5 ببساطة لأنه يُنهي الذاكرة قبل أن يبدأ التدريب أصلاً.
ثلاثة مصادر للتحسين تتضافر لإنتاج هذه النتائج: أولاً Expert Parallelism الذي يوزّع أوزان الخبراء عبر GPUs وينشئ بُعد موازاة مستقلاً (moe_mesh) يعمل جنباً إلى جنب مع data parallelism — على 8 GPUs يعمل ep=8 مع dp=8 معاً، فكل GPU يحمل 1/8 فقط من الخبراء بينما يُدرّب على shard منفصل من البيانات. ثانياً DeepEP الذي يدمج عمليات all-to-all dispatch في GPU kernels مُحسّنة تُداخل الاتصال مع الحساب بدلاً من تنفيذهما بالتتابع. ثالثاً TransformerEngine kernels التي تُسرّع attention والطبقات الخطية وRMSNorm عبر جميع طبقات النموذج لا طبقات MoE فقط. التسلسل التطوري يصبح واضحاً: v4 (eager for-loop) → v5 (grouped_mm) → NeMo AutoModel (DeepEP + GMM + TransformerEngine).
نقطة تستحق الانتباه: أرقام NeMo AutoModel في الـ 30B benchmarks تستخدم balanced routing gate الذي يوزّع tokens بالتساوي عبر الخبراء، بينما v4 وv5 يستخدمان router الأصلي على dummy tokens عشوائية. المبرر المنطقي هو أن النموذج المُدرَّب جيداً يتقارب نحو توزيع متوازن للخبراء عبر load-balancing loss، لذا يعكس balanced routing نقطة التشغيل الحقيقية. لكن هذا يعني أن المقارنة ليست في ظروف متطابقة تماماً — شيء يجب أخذه بعين الاعتبار عند تفسير فارق 3.7× على أنه ضمانة مطلقة لحالتك.
إن كنت تعمل على fine-tuning نماذج MoE وتصطدم بجدران الذاكرة أو بطء التدريب، فإن NeMo AutoModel يقدّم مساراً عملياً يبدأ بسطر واحد ولا يتطلب التخلي عن بنية HuggingFace التي اعتدت عليها. النماذج المحفوظة تبقى متوافقة مع منظومة inference القياسية — وهذا بالضبط ما يجعل التبني قراراً بلا مخاطر تقنية كبيرة.