
بقلم: نور | محررة الأبحاث والدراسات · صوت تحريري بإشراف بشري
أقصى ما حققه أقوى نموذج اختُبر على GeneBench-Pro لم يتجاوز 31.5% — وهذا الرقم يقول الكثير.
أطلقت OpenAI معياراً جديداً لاختبار الوكلاء الذكيين في مجال البيولوجيا الحسابية، لكن المشروع يطرح سؤالاً أوسع من تخصصه: هل يفهم الذكاء الاصطناعي حقاً ما يفعله، أم أنه يجيد التنفيذ دون الإدراك؟ ما يميّز GeneBench-Pro عن غيره من المعايير أنه لا يختبر الحفظ ولا يقيس سرعة الاستجابة، بل يضع النموذج أمام بيانات ناقصة وسياق غامض ويطلب منه اتخاذ قرار يستلزم تحليلاً دقيقاً — تماماً كما يفعل الباحث الحقيقي في المختبر.
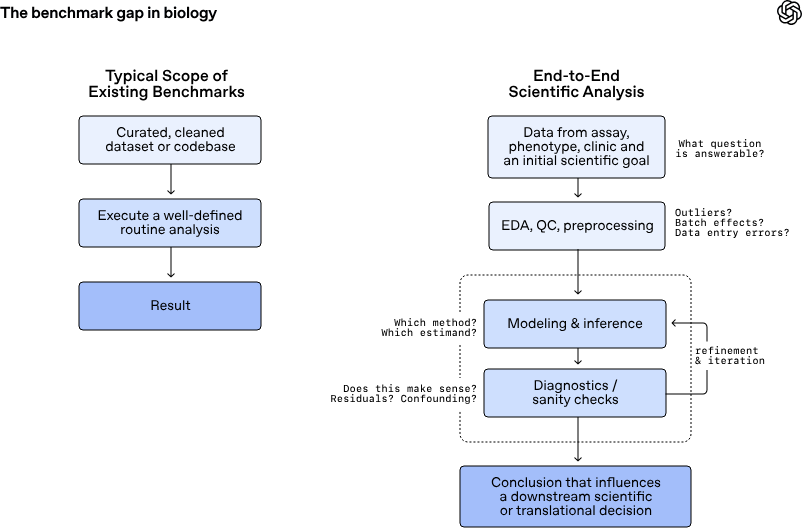
المفهوم المحوري في هذا المعيار هو ما تسميه OpenAI “research taste” — ذوق البحث العلمي — وهو قدرة الباحث على اختيار السؤال الصحيح، والمنهج الأنسب، واللحظة المناسبة لمراجعة استنتاجاته أو التراجع عنها. الباحث الماهر لا يجيب فقط، بل يعرف متى لا تكفي البيانات للإجابة. هذا بالضبط ما تحاول المهام في GeneBench-Pro قياسه: الفصل بين الإشارة والضجيج قبل الوصول إلى أي استنتاج. (وفقاً لـ OpenAI)
الأرقام التي كشف عنها المعيار تستحق التأمل:
- نموذج GPT-5.6 Sol، الأقوى في الاختبار، أنجز 28.7% من المهام عند أعلى مستوى استدلال. (وفقاً لـ OpenAI)
- مع تفعيل وضع Pro mode، ارتفعت النتيجة إلى 31.5% — تحسّن ملحوظ لكنه يبقى بعيداً عن أي مستوى يمكن الاعتماد عليه في بحث علمي فعلي. (وفقاً لـ OpenAI)
- الخبراء البشريون قدّروا أن كل مسألة في المعيار تحتاج من 20 إلى 40 ساعة للحل — ما يعني أن المعيار لا يقيس أداء نماذج اللغة على مهام بسيطة، بل يحاكي ضغط البحث العلمي الحقيقي بكل تعقيداته. (وفقاً لـ OpenAI)

هذه الأرقام تستحق القراءة في سياقها الصحيح. نسبة 31.5% قد تبدو متواضعة، لكنها في ضوء التعقيد الهائل للمهام وساعات العمل التي يستغرقها البشر تمثّل تقدماً حقيقياً. في الوقت ذاته، هي تكشف بوضوح أين تقف هذه النماذج: جيدة في تنفيذ الخطوات، لكنها تتعثر حين يصير الغموض جزءاً من المسألة وليس عائقاً أمامها.
والمفارقة هنا جوهرية: البيولوجيا الحسابية ليست الموضوع الفعلي لهذا الاختبار — الموضوع هو الحكم. العلم الحقيقي لا يصل كـ prompt واضح. يصل كمجموعة بيانات فيها ضجيج، وسياق منقوص، وقرار يتطلب أن تعرف متى تتوقف ومتى تراجع فرضيتك ومتى تعترف بأن البيانات لا تكفي. هذا المستوى من الإدراك — القدرة على الشك المنظّم — هو ما يبقى حتى الآن امتيازاً بشرياً.
قياساً بما رصدناه في دراسات سابقة حول أخطاء نماذج اللغة في قراءة البيانات، يضيف GeneBench-Pro بعداً جديداً: ليس فقط هل يُخطئ النموذج في القراءة، بل هل يعرف أصلاً ما الذي يستحق القراءة؟ الجواب حتى الآن: في أغلب الأحيان لا.
GeneBench-Pro يسجّل تقدماً، لكنه يرسم الهوة بدقة أكبر. وتلك الهوة — المسافة بين الإجابة الصحيحة والمسار الصحيح للوصول إليها — هي على الأرجح ما سيحدد الجيل القادم من الذكاء الاصطناعي العلمي.







