بقلم: يوسف | محرر أدوات الذكاء الاصطناعي · صوت تحريري بإشراف بشري
إذا كنت تبني نظام RAG على مستوى المؤسسات، فالمشكلة ليست في استرداد النصوص — المشكلة في تحديد المكان الدقيق داخل المستند الذي يجيب فعلاً عن السؤال. هذا ما تحله بنية Anchor Detection: خط أنابيب ثلاثي المراحل يشغّل مكتشف الكلمات المفتاحية ومكتشف التضمينات معاً بالتوازي، ثم يسلّم الناتج لاستدعاء LLM واحد في النهاية يحكم ويرتّب ويكتب أسبابه.
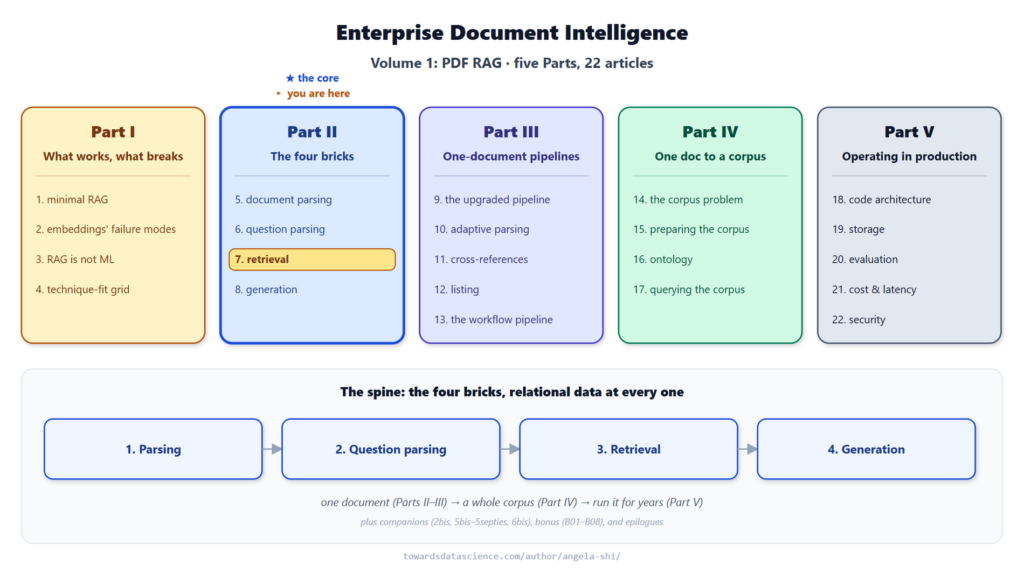
الفكرة مأخوذة من سلسلة Enterprise Document Intelligence التي تبني نظام RAG من أربعة أجزاء: التحليل، وتفسير الأسئلة، والاسترداد، والتوليد. المقال الحالي هو الجزء الثاني من قسم الاسترداد، ويعمل على جدولين هيكليين: line_df الذي يحمل أسطر المستند، وtoc_df الذي يحمل فهرس المحتويات.
لنأخذ مثالاً حياً. المستخدم يكتب “How is attention computed?” على ورقة Attention Is All You Need (Vaswani et al. 2017، 15 صفحة، 22 إدخالاً في الفهرس على 3 مستويات). ست صفحات مرشّحة تتضمن كلمة attention. الصفحة الصحيحة هي التي تذكر softmax وquery وkey وd_k معاً، وتقع تحت القسم المسمى “Scaled Dot-Product Attention” في الفهرس. مكتشف الكلمات المفتاحية وحده يعثر على المجموعة المرشّحة، ومكتشف التضمينات يفعل الشيء ذاته، لكن لا أحدهما يستطيع وحده تحديد الصفحة الصحيحة. يحتاج الأمر إلى قراءة المرشّحين جنباً إلى جنب مع قسمهم في الفهرس، واختيار الأنسب مع سبب مقروء يمكن مراجعته لاحقاً (وفقاً لـ Towards Data Science).

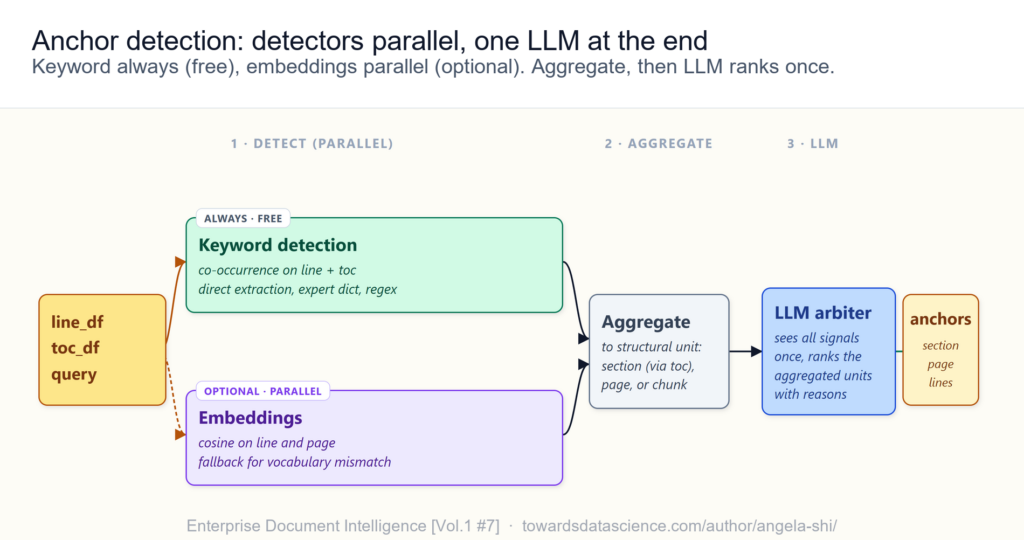
قبل الدخول في التفاصيل، ثمة ثلاثة مبادئ تحكم التصميم بأكمله: الكلمات المفتاحية تعمل دائماً لأنها مجانية وحتمية ولا مبرر لتجاهل إشارتها. التضمينات تعمل بالتوازي كإشارة ثانوية اختيارية مفيدة حين يكون هناك تباين في المفردات أو حين السؤال مفاهيمي لا لفظي — وبما أن الفهارس محسوبة مسبقاً، التكلفة عند وقت الاستعلام هي ميكروثوانٍ. أما LLM فيأتي مرة واحدة فقط في النهاية، يرى الفهرس وضربات الكلمات المفتاحية وضربات التضمينات والانتماء الهيكلي لكل مرشّح في استدعاء واحد.
لهذا القرار — وضع LLM في النهاية لا في المنتصف — نتيجتان تصميميتان جوهريتان. أولاً: النموذج يستنتج العلاقات الضمنية في الفهرس تلقائياً؛ إذا سأل المستخدم “ما الذي يحدث إذا خرجنا مبكراً؟” وكان الفهرس يحمل “Termination” و”Penalties” دون أي قسم باسم “Exit”، فإن النموذج يختار كليهما عند التصنيف دون الحاجة لخطوة “استنتاج الفهرس” المستقلة. ثانياً: النموذج يحلّ تطابقات العناوين الخفية؛ إذا كان السؤال عن “القسط” والقسم المعني عنوانه “ملخص العقد”، فلن تتطابق أي كلمة مفتاحية مع العنوان، لكن النموذج الذي يرى أسطر المحتوى الملحقة بذلك القسم سيختاره على أي حال.
يوضّح المقال الأصلي كيف يعمل الكشف على toc_df بمكتشفَين: مطابقة الكلمات المفتاحية في عناوين الأقسام (المكتشف الافتراضي، مجاني ودائم)، ومطابقة التضمينات اختيارياً. حين يُشغَّل مكتشف الكلمات المفتاحية على ورقة Transformer بكلمة “attention”، يعيد خمسة أقسام نظيفة في صفر ميلي ثانية ودون أي استدعاء LLM أو حساب تضمينات. أما دالة reason_on_toc — التي تمرر الفهرس بالكامل إلى LLM وتسأله عن الأقسام الأكثر صلة — فهي ليست خطوة مستقلة في الإنتاج، بل تُطوى داخل استدعاء المحكّم الأخير. حجم toc_df الصغير هو ما يجعل هذا ممكناً؛ عكس line_df الذي قد يحمل اثني عشر ألف سطر ويستحيل تمريره كله لنموذج لغوي.
على الورقة ذاتها، حين يُسأل النموذج “How does the Transformer handle long-range dependencies between words?”، يختار القسمين [4] و[11] ويكتب حرفياً: “The question about how the Transformer handles long-range dependencies between words is best addressed in sections that discuss the attention mechanism (Section 4) and the reasoning behind using self-attention (Section 11). The attention mechanism is key to managing long-range dependencies, while Section 11 likely provides insights into its necessity and effectiveness.” هذه الجملة هي ما يجعل النتيجة قابلة للتدقيق — طريقة الكلمات المفتاحية تعيد قائمة أقسام دون أن تخبرك لماذا (وفقاً لـ Towards Data Science).
الفرق بين التضمينات والاستنتاج يستحق التوقف عنده. نموذج التضمينات يلتقط “exit early ≈ termination” عبر التشابه الدلالي، لكنه لا يستطيع استنتاج “exit early يعني وجود penalties”. هذا استنتاج لا تشابه، وهو ما يبرر وجود LLM في المرحلة الثالثة حتى حين تكون إشارات الكلمات المفتاحية والتضمينات كافية للعثور على المرشّحين.
خط الأنابيب كاملاً يعمل على المبدأ التالي: كل ما هو رخيص يعمل دائماً، وكل ما هو مكلف يعمل مرة واحدة في النهاية فقط. التكلفة الفعلية لاستدعاء المحكّم هي بضعة آلاف من الرموز لفهرس نموذجي، وبضع مئات من الميلي ثانية من الكمون — وهي تكلفة تُدفع مرة واحدة فقط بدلاً من استدعاءات متعددة في منتصف خط الأنابيب. الجزء التالي من السلسلة (Article 7C) يتناول استدعاء المحكّم بالكامل: كيف يتحول المرشّحون المجمّعون إلى إجابة مرتّبة مع JSON ناتج.
إذا كنت تبني أنظمة RAG وتبحث عن بنية قابلة للتدقيق وفعّالة من حيث التكلفة، فهذا النهج يستحق الدراسة. تقليص استدعاءات LLM إلى واحد في النهاية ليس مجرد توفير — إنه إعادة رسم واضحة لمسؤوليات كل مرحلة في خط الأنابيب.