بقلم: نور | محررة الأبحاث والدراسات · صوت تحريري بإشراف بشري
حين تُدرَّب نماذج اللغة الكبيرة باستخدام التقطير الذاتي على السياسة (on-policy self-distillation)، فإنها تحقق نتائج مبهرة في معيار pass@1 — لكن ورقة بحثية نُشرت على arXiv في 24 يونيو 2026 تكشف أن هذا التحسّن ينطوي على ثمن خفيّ: النموذج يفقد تدريجياً قدرته على توليد إجابات متنوعة وظيفياً، ويتمركز حول الأنماط السائدة في توزيعه الأصلي بدلاً من استكشاف استراتيجيات بديلة.
الفكرة الجوهرية التي يطرحها الباحثون Andrei Liviu Nicolicioiu وMohammad Pezeshki وAaron Courville هي أن النموذج في التقطير الذاتي يؤدي دورَي المعلّم والطالب في آنٍ واحد: المعلّم يُشرَط على مثال صحيح مسحوب (sampled demonstration)، ثم يُقيّم مخرجات الطالب على مستوى الرمز token بدقة عالية. المشكلة ليست في الآلية بحد ذاتها، بل في التحيزات المتراكمة التي تولّدها: حين يُقيّم المعلّمُ مخرجاتِ الطالب وهو مشرَط على مثاله الخاص، فإنه يمرر تحيزات النموذج عبر نفسه بشكل دوري، ما يُشكّل حلقة تغذية راجعة تُعزّز الأنماط المهيمنة وتُهمّش البدائل.
التحليل النظري في الورقة يكشف السبب الرياضي وراء هذا السلوك: السياسة المثلى في التقطير الذاتي تُرجّح التوزيع الأصلي بدرجة المعلومات المتبادلة الشرطية النقطية (pointwise conditional mutual information) بين مخرجات الطالب والمثال الصحيح المستخدَم كسياق. هذا مختلف جوهرياً عن التعلم المعزّز على السياسة (RL) في صيغته المثلى، الذي يحافظ على النسب الاحتمالية بين المخرجات الصحيحة المتكافئة — أي لا يفضّل حلاً صحيحاً على آخر صحيح بالقدر ذاته. في المقابل، التقطير الذاتي يُضخّم الفجوات الاحتمالية القائمة بين هذه الحلول، فيُمركز الكتلة الاحتمالية حول الأنماط الغالبة ويُقلّص حضور البقية.
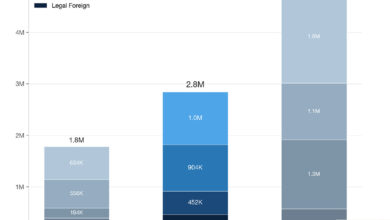
التحقق التجريبي جاء على مستويين: مهمة إيجاد المسار في الرسم البياني (graph path-finding) كبيئة خاضعة، ومعايير الإجابة عن الأسئلة العلمية (science question-answering benchmarks). (وفقاً للورقة البحثية) في البيئتين، حقّقت النماذج المُقطَّرة ذاتياً أداءً مماثلاً أو أعلى من التعلم المعزّز على مؤشر pass@1 — أي الإجابة الصحيحة في المحاولة الأولى. لكن حين أصبح المقياس pass@k — أي هل يُنتج النموذج إجابة صحيحة واحدة على الأقل من بين k محاولات — ظهر الفارق جلياً: منحنيات pass@k للنماذج المقطَّرة تسطّحت (flatten)، أي أن زيادة عدد المحاولات لم تُسفر عن تحسّن يُعتدّ به في الدقة الكلية.
الأخطر من ذلك أن التنوع الدلالي والوظيفي للمخرجات تراجع بشكل ملحوظ. حين واجهت النماذج المُقطَّرة مشكلات من خارج التوزيع (out-of-distribution) — أي مسائل تتطلب استراتيجيات متباينة عمّا رُؤي في التدريب — كانت النماذج المُقطَّرة أضعف أداءً، لأنها فقدت المرونة في استكشاف حلول بديلة. بعبارة أخرى: النموذج يُتقن ما يعرفه، لكنه يفشل حين تستدعي المهمة التفكير خارج النمط المهيمن.
هذه النتيجة تُعيد طرح سؤال جوهري أمام كل من يعمل على fine-tuning أو alignment للنماذج الكبيرة: هل تُعظِّم pass@1 فحسب، أم تحتاج نماذجك إلى تنوع حقيقي في الاستراتيجيات؟ إذا كان النظام يُشغَّل في سياقات متوقعة وموحّدة، فالتقطير الذاتي أداة فعّالة وكفؤة. لكن إن كانت التطبيقات تستدعي التعامل مع مدخلات متغيرة أو توليد حلول متعددة المسالك — كالبرمجة الاستكشافية، والتخطيط في بيئات متغيرة، ومهام الإبداع المفتوح — فإن التعلم المعزّز يبقى الخيار الأجدر من الناحية النظرية والتطبيقية معاً.
ما يميز هذا البحث أنه لا يكتفي برصد الظاهرة تجريبياً بل يُؤطّرها نظرياً بدقة، ويُنبّه إلى أن التحيز لا يظهر في مؤشرات الأداء السطحية بل يتجلى فقط حين تُضغط النماذج بمهام تتطلب تعدداً استراتيجياً. وهذا تنبيه عملي مباشر لأي فريق يعتمد التقطير الذاتي في pipeline التدريب دون قياس التنوع بمؤشرات مستقلة عن pass@1.