بقلم: سارة | محررة نماذج الذكاء الاصطناعي · صوت تحريري بإشراف بشري
كشفت OpenAI النقاب عن ثلاثة نماذج صوتية متقدمة ضمن واجهة Realtime API، حيث يبرز GPT-Realtime-2 كأول نموذج محادثة صوتية يمنح المطورين تحكماً مباشراً في مستوى التعقيد والسرعة.
النموذج الجديد يمعالج الصوت بشكل شامل من المدخل للمخرج دون تجزئة العملية لخطوات منفصلة كالتعرف على الكلام ثم توليد النص وتحويله لصوت. المفتاح الجديد هو معامل “reasoning effort” الذي يتيح ضبط مستوى التفكير من “minimal” للاستجابات السريعة وصولاً إلى “xhigh” للتحليل العميق.

- GPT-Realtime-2: النموذج الرئيسي للمحادثة الصوتية مع إعدادات التفكير القابلة للتخصيص من أربعة مستويات
- GPT-Realtime-Translate: متخصص في الترجمة الفورية بدعم أكثر من 70 لغة إدخال و13 لغة إخراج
- GPT-Realtime-Whisper: مُحسن لتحويل الكلام إلى نص مع دقة عالية ومعالجة سريعة
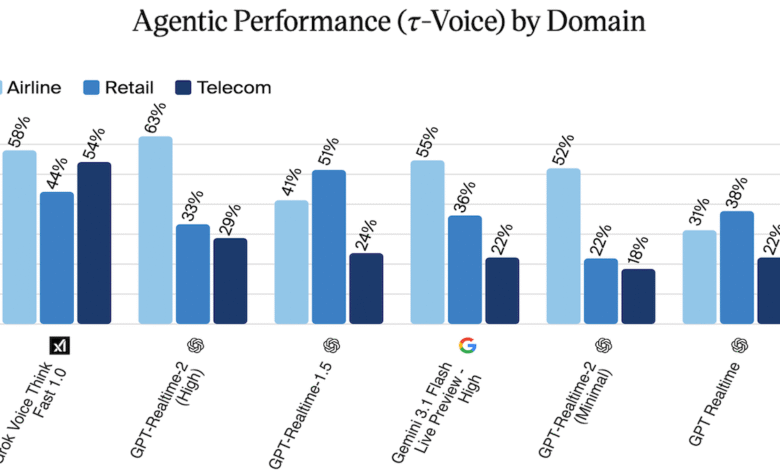
النتائج المعيارية تضع GPT-Realtime-2 في المقدمة حيث تصدر مؤشر Scale AI Audio MultiChallenge ومؤشر Artificial Analysis Conversational Dynamics. البيانات تكشف أن زمن الاستجابة يتراوح من 1.12 ثانية عند الحد الأدنى من التفكير إلى 2.33 ثانية عند المستوى العالي (وفقاً لـ The Batch).
في اختبار Big Bench Audio، حقق GPT-Realtime-2 بمستوى التفكير العالي نسبة 96.6% متعادلاً مع Gemini 3.1 Flash Live Preview من Google، بينما تفوق عليه Step-Audio R1.1 Realtime بنسبة 97.6% (وفقاً لـ The Batch).
الإشكالية الحقيقية تكمن في إدارة هذا المقايضة بين السرعة والجودة. مضاعفة زمن الاستجابة مقابل تحسين فهم السياق قد يكون مقبولاً في التطبيقات التعليمية، لكنه كارثي في خدمة العملاء الفورية. هذا التحكم المرن يفتح آفاقاً جديدة للتطبيقات المتخصصة لكنه يضع عبء الاختيار الصحيح على عاتق المطورين.







